모델 성능 평가 - Confusion Matrix
Confusion Matrix를 사용해야 하는 이유
- 다양한 평가 지표들$(Recall,\, Precision,\, F_{1} Score,\, F_{\beta} Score)$를 통해서 분류 모델(Classification model)이 얼마나 정확하게 분류하는지 확인할 수 있게 된다.
- 모델이 어떤 종류의 오류를 만드는지 파악하고, 특히 FP(False Positives), FN(False Negatives)를 식별하여 모델를 향후의 개선하는데 도움을 준다.
- 클래스의 불균형 문제에서 모델의 성능을 정확하게 평가할 수 있다. 예를 들면 총 100개의 Testset중 폐렴의 걸린 사람 5명 정상인 95명에 대해서 학습모델이 모두 건강한 사람이라고 예측해도 정확도는 $\frac{95(맞은\,개수)}{100(전체\,데이터)}$ 로 총 95%의 정확도를 가진다.
Confusion Matrix란
아래는 Confusion Matrix로 모델의 예측 결과와 실제 결과를 비교하여 다양한 평가 메트릭을 계산하는 데 도움을 줍니다. 그리고 2개 이상의 클래스로 구성된 분류 문제에 적합합니다.

- True Positive(TP): 실제정답(Ground Truth)과 예측결과(predict value)가 일치할때 예측값이 양성클래스로 분류한 경우
- True Negative(TN): 실제정답과 예측결과가 일치할때 예측값이 음성 클래스로 분류한 경우
- False Positive(FP): 실제정답과 예측결과의 값이 일치하지 않고 이때 예측값을 양성클래스로 분류한 경우
- False Negative(FN): 살제정답과 예측결과의 값이 일치하지 않고 이때 예측값을 음성클래스로 분류한 경우
위에 4가지 경우의 주요 항목들을 통해서 오류 경향을 세밀하게 분석할 수 있다.
Recall
Recall은 실제 양성 중에서 모델이 양성으로 올바르게 분류한 비율을 나타냅니다. 따라서 양성 클래스 중 얼마나 많은 것을 감지했은지를 측정할때 사용됩니다. 공식은 $\frac{TP}{TP+FN}$로 예를 들면 암의 걸린 환자를 예측하는 모델을 만들었을때 모델이 실제 감기의 걸린 사람들중 얼마나 많은 사람들을 예측했는지 확인할 수 있게 해준다.
Precision
Precision는 모델이 양성클래스로 예측한 것 중에서 실제 양성인 비율을 나타냅니다. 식은 $\frac{TP}{TP+FP}$을 나타내고 암의 걸렸다고 예측한 것들중에 얼마나 많은 것이 정확히 양성인지 측정해준다.
Recall과 Precision은 실제로 많이 헷갈리는 공식입니다. 따라서 이해하기 쉽게 예를 들면 병원 입장에서는 암에 안걸렸는데 암에 걸렸다고 하는 것보다 암의 걸렸는데 암의 걸리지 않았다고 예측하는 것이 더 위험하기 때문에 이때 Recall를 통해서 실제 암환자 중 얼마나 많은 암환자들을 예측했는지를 확인하는 것이고, 그러면 모델이 암의 걸렸는데 암의 걸리지 않았다고 하는 것이 위험하고 생각하고 모든 경우를 다 암의 걸렸다고 예측해버릴 수도 있기 때문에 이런 경우를 대비해서 Precision를 사용하여 모델이 암이라고 예측한 사람들중 실제로 암의 걸린 사람들의 비율을 측정하는 것입니다.
$F_{1}\, Score$
$F_{1}\, Score$는 Recall과 Precision의 조화평균으로 공식은 다음 $\frac{2\times Recall \times Precision}{Recall + Precision}$ 으로 곱하기 2를 제외하면 전기회로의 병렬회로의 전체 저항값을 구하는 공식과 유사하다. 하지만 병렬회로의 전체저항을 구하게 되면 전체 저항의 값이 저항이 작은값 쪽으로 치우치는 경향이 있기 때문에 $F_{1}$에서는 곱하기 2를 해줌으로서 값이 Recall, Precision 어느쪽으로 치우치지 않게 해주는 것 같다.(개인적인 생각)
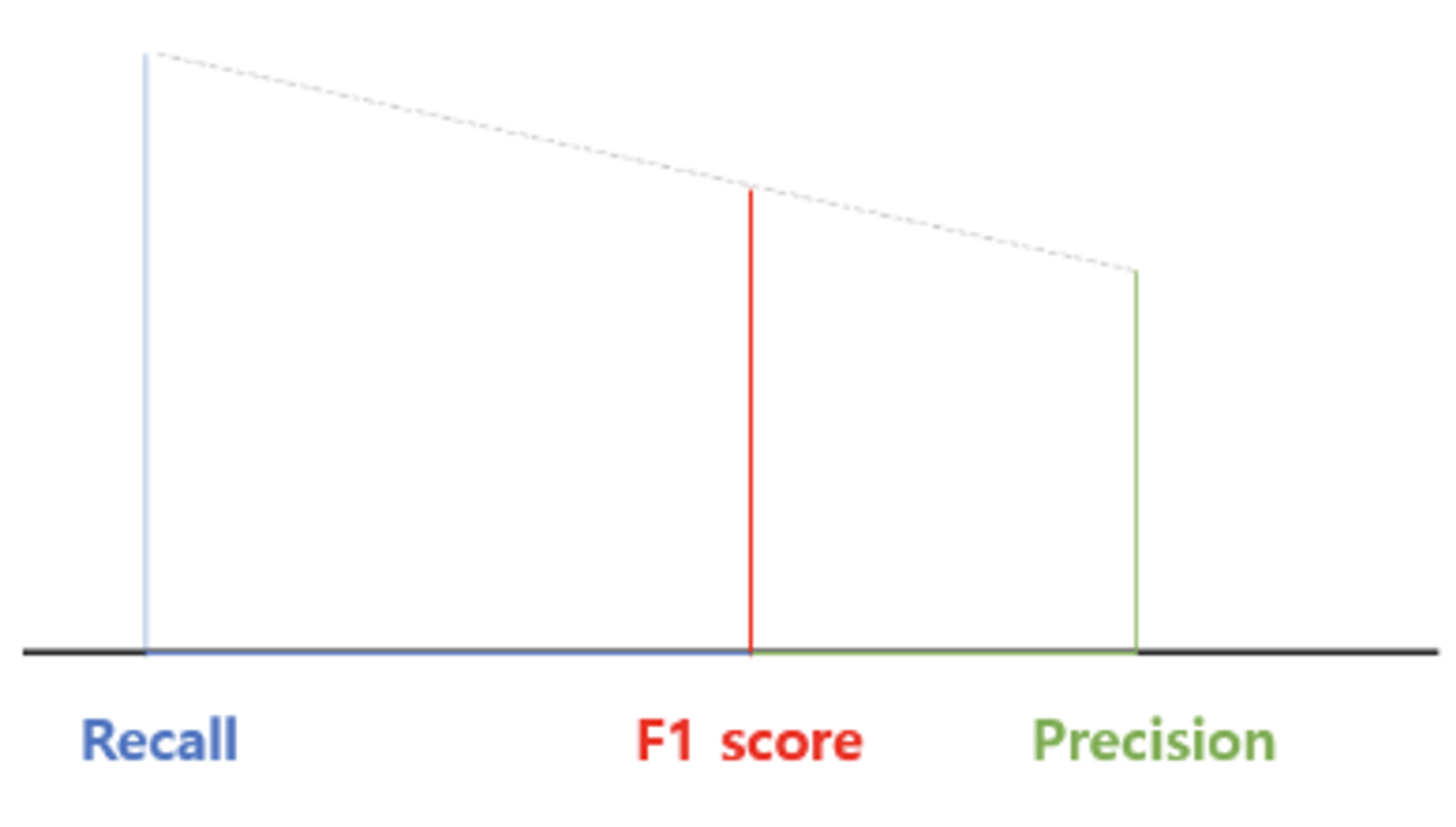
$F_{\beta}\, Score$
$F_{\beta}\, Score$는 ${\beta}$값을 컨트롤 하면서 Recall과 Precision중 어느쪽에 비중을 더 줄 것인지를 나타내는 내는 평가 방식으로 식은 다음 $\frac{(1 + \beta) \times (Recall \times Precision)}{\beta \times (Recall + Precision)}$과 같고 ${\beta}$가 1이면 위의 $F_{1}$과 값이 일치하고 만약 ${\beta}$가 1보다 크면 Recall의 비중을 더 두는 것이고 만약 ${\beta}$가 1보다 작으면 Precision의 값의 더 중점을 두는 것으로 ${\beta}$값은 사용자가 자신의 모델의 맞게 선택해서 사용하면 된다.
Example
다음 사진과 같이 모델이 예측을 하였을때 $Recall, Precision, F_{1}\,Score$를 계산해보자
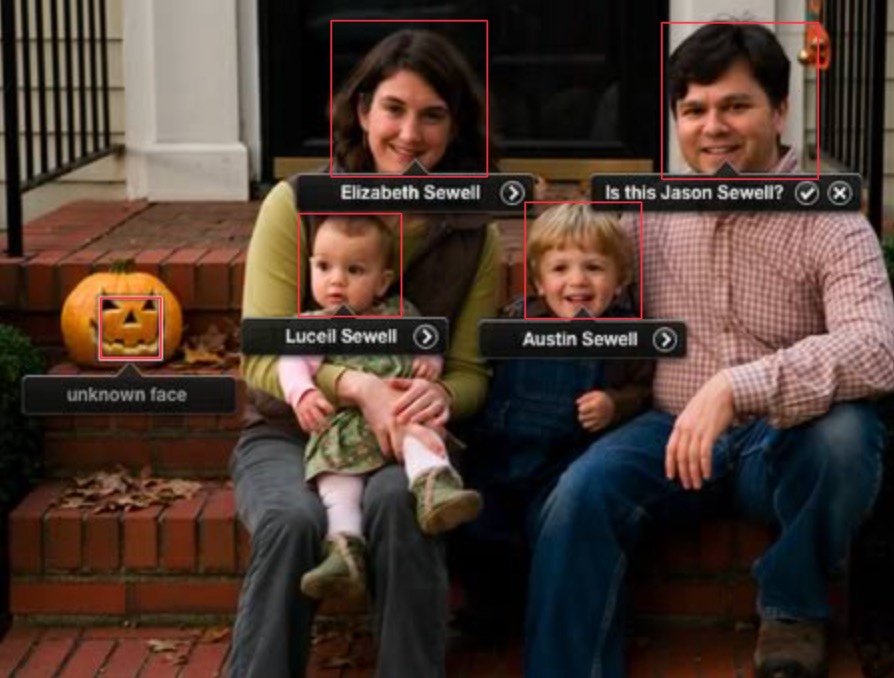
정답:
- Recall = $\frac{4(모델이\,사람이라고\,예측한\,것\,중\,실제\,사람인\,것)}{4(실제\,사람\,얼굴\,개수)} = $ 1(100%)
- Precision = $\frac{4(모델이\,사람이라고\,예측한\,것\,중\,실제\,사람인\,것)}{5(모델이\,사람이라고\,인식한\,개수)} =$ 0.8(80%)
- $F_{1}\,Score$ = $\frac{2\times(1\times0.8)}{1+0.8} =$0.8889(약 89%)