통계학 - 정규분포(Normal Distribution)
Normal Distribution이란
정규분포 또는 가우시안 분포(Normal or Gaussian Distribution)은 통계학과 확률 이론에서 중요하고 실제로 인공지능, 컴퓨터 비전 분야에서 널리 사용되는 확률 분포중 하나입니다. Normal Distribution은 연속확률분포의 확률밀도함수(PDF)중 하나로 다양한 자연환경에서 나타나는 데이터의 분포를 설명하는데 사용이 됩니다.
Shape
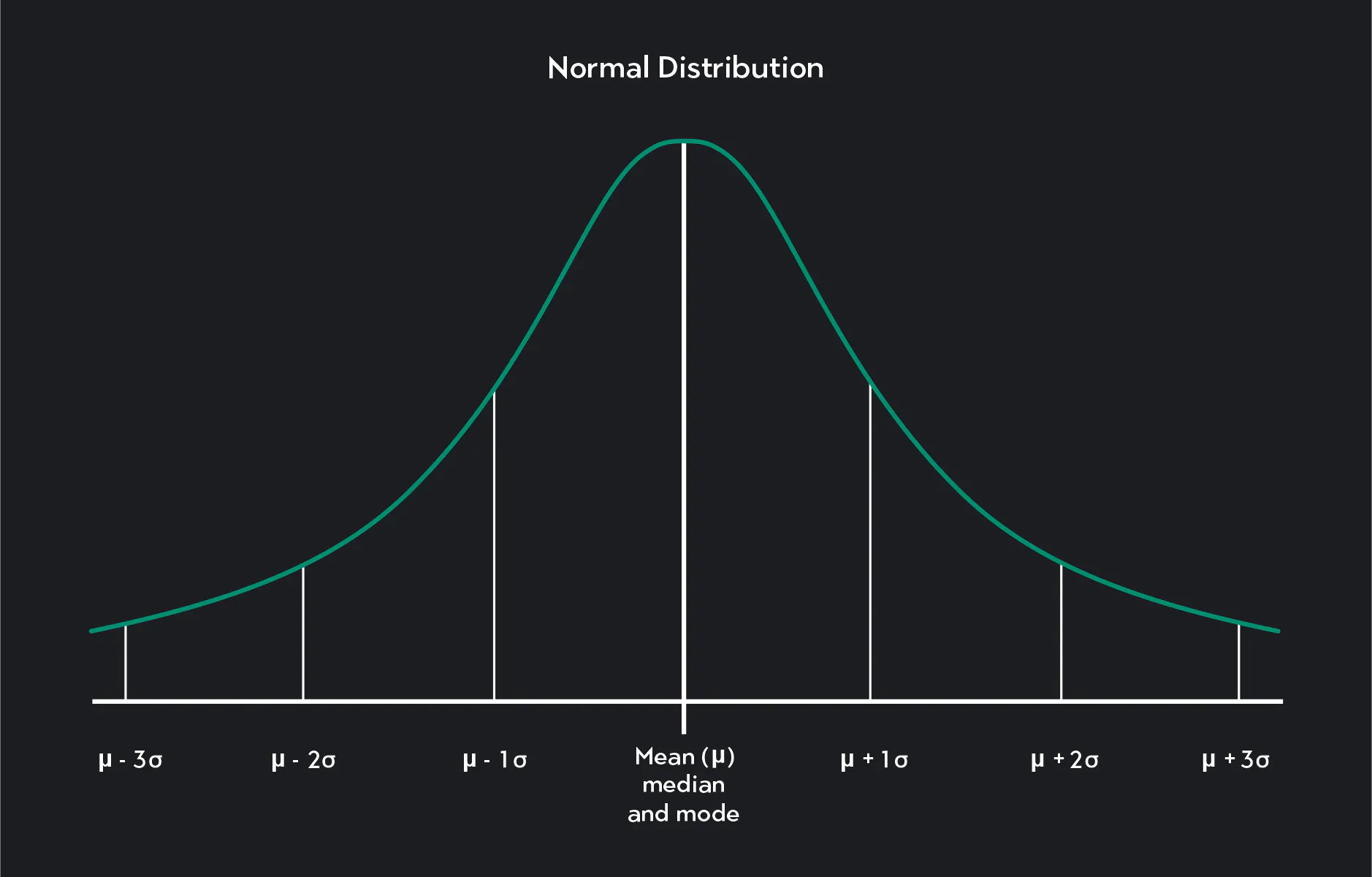
그림과 같이 정규분포는 종모양(Bell shape)의 형태를 가지면서 좌우가 서로 대칭인 모양을 가지고 있습니다. 그리고 처음부터 끝까지의 넓이의 값은 항상 1을 가집니다.
Formula
$f(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \cdot e^{-\frac{(x - \mu)^2}{2\sigma^2}}$
이때:
- $f(x)$ 는 확률 변수 $x$의 확률 밀도 함수입니다.
- $\mu$ 는 분포의 평균을 나타냅니다.
- $\sigma$ 는 분포의 표준편차를 나타냅니다.
- $e$ 는 자연 상수(약 2.71828)입니다.
- $\pi$ 는 원주율(약 3.14159)입니다.
하지만 위에 식은 너무 복잡하고 수많은 정규분포에 대해서 매번 해당 공식에 대입해서 풀 수 없기 때문에 아래에서 모든 정규분포를 하나의 통일된 표준정규분포(Standard Normal Distribution)로 표준화(Standardization)를 진행하여 문제를 풀면 비교적 간단하게 문제를 해결할 수 있다.
Notation
표기는 $N(\mu,\,\sigma^2)$ 로 표기 합니다. 따라서 위에 그림을 보면 평균에 해당하는 Mean$(\mu)$을 중심으로 표준편차$(\sigma)$ 만큼 좌우 대칭적으로 점차 확률밀도가 줄어드는 것을 확인 할 수 있습니다. 따라서 만약 학생들의 시험 성적의 평균이 70점이고, 표준편차가 10점이면 $N(70,\,10^2)$ 로 표기할 수 있습니다.
Propertie of Normal Distribution
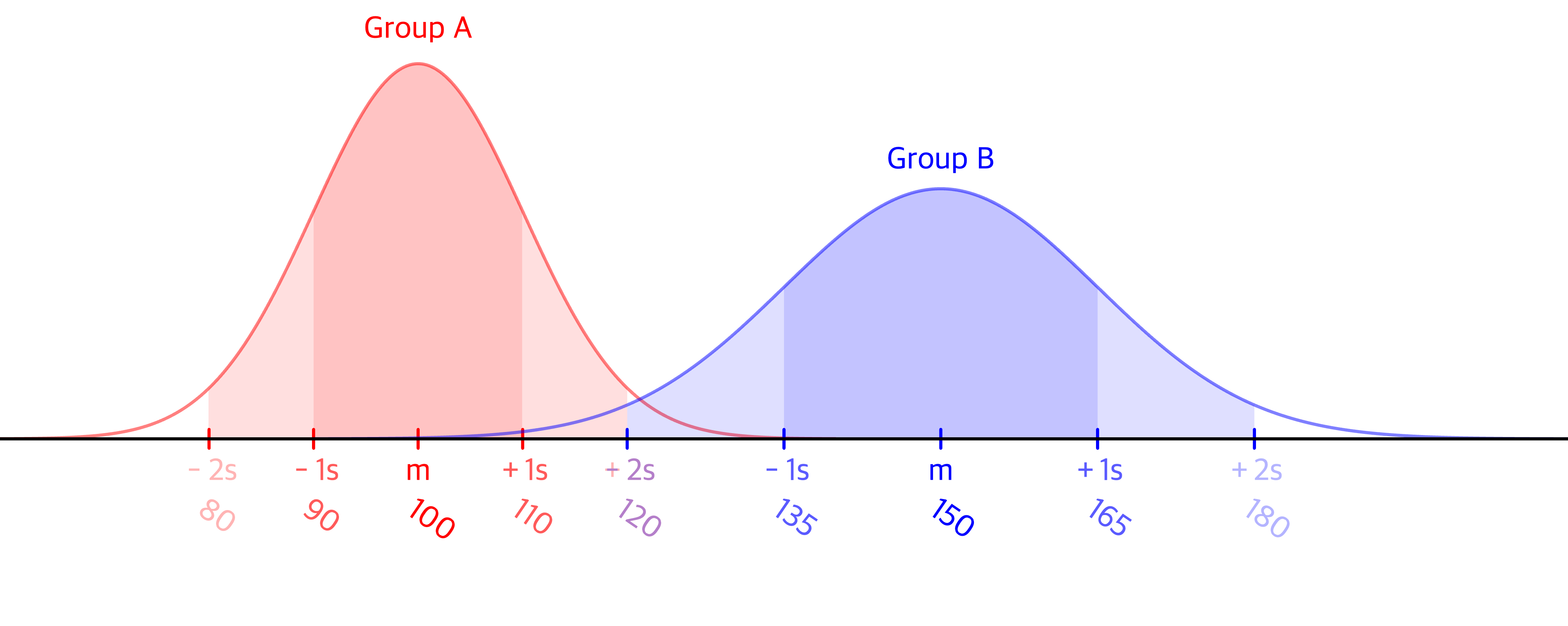
그림과 같이 만약 Group A의 정규분포는 $N(100,\,10^2)$을 따르고 Group B의 정규분포는 $N(150,\,15^2)$을 가질때, Group A의 대한 $P(90≤x≤110)$랑 Group B의 대한 $P(135≤x≤165)$는 항상 같은 값을 가집니다.
표준정규분포(Standard Normal Distribution)
같은 정규분포이지만 아래 그림과 같이 표준정규분포(Standard Normal Distribution)은 평균이 0이고 표준편차가 1인 정규분포입니다.
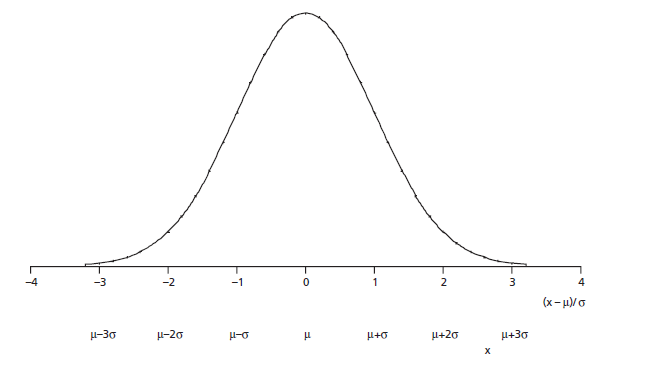
따라서 표기법(Notation)은 $N(0,\,1^2)$ 로 표기합니다.
Standardization
기존 정규분포를 표준정규분포로 바꾸는 과정을 표준화(Standardization)라고 한다.
Formula
$Z = \frac{X\, -\,\mu}{\sigma}$
이때:
- $Z$ 는 표준화된 값(Z-점수 또는 Z-Score)를 나타냅니다.
- $X$ 는 원시 데이터 값입니다.
- $\mu$ 는 원시 데이터의 평균입니다.
- $\sigma$ 는 원시 데이터의 표준편차입니다.
해당 링크의 표준정규분포표을 통해서 모든 정규분포의 관찰 될 확률들을 계산할 수 있다.
위의 Standard Normal Distribution과 Standardization은 딥러닝에서 Batch Normalization, Computer Vision의 에지 추출의 영교차이론 등 컴퓨터 비전과 딥러닝 분야에서 정말 많이 등장하기 때문에 잘 알고 있어야 합니다.