Paper Review - FCN(Fully Convolutional Networks for Semantic Segmentation)
[Reference] CVPR2015 FCN Paper
Abstract
해당 논문은 key insight는 임의의 크기의 입력을 받아들이고 효율적인 추론과 학습을 통해 해당 크기의 출력을 생성하는 “fully convolutional” 네트워크를 구축하는 것입니다. 또한 AlexNet, VGG16, GoogLeNet과 같은 현대적인 networks를 수용하여 fully convolutional network를 구성했으며, 사전 학습된 representations를 변환하여 segmentation task에 적용하였습니다.
해당 논문은 deep, coarse layer에서 semantic 정보와 shallow, fine layer에서의 appearance 정보를 결합한 skip architecture를 정의하였습니다. 그 결과 SOTA(state-of-art) segmentation를 달성하였습니다 (fine이 섬세함을 뜻하고, coarse는 fine의 반대말로 rough하면서 non-smooth함을 나타낸다. 쉽게 설명하면 fine은 섬세하게 보는 것이고, coarse는 섬세하지 않지만 전반적으로 보는 것을 의미한다.).
1. Introduction
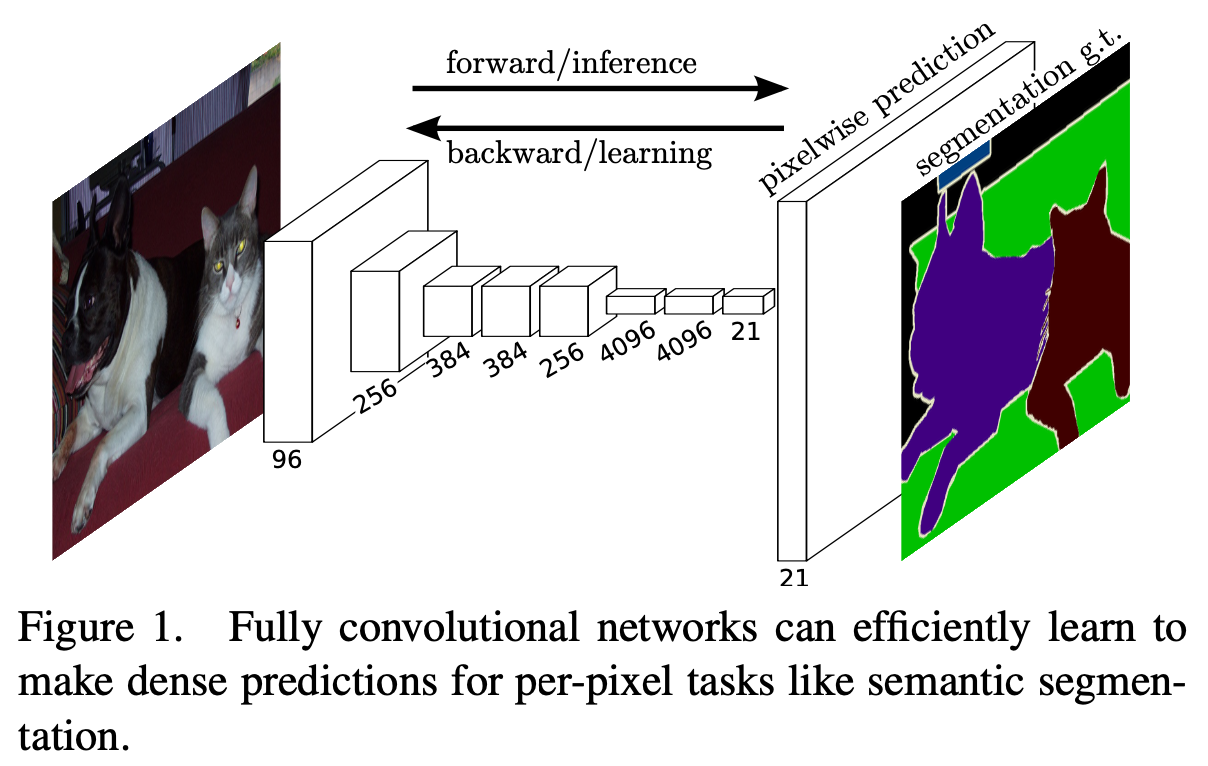
Convolution network는 물체 인식에서 발전을 주도하고 있으며, Convnet는 whole-image에 대한 classification를 향상시킬 뿐만 아니라 structured ouput의 local task에서도 전진을 이루고 있습니다. (structured output는 output 자체가 단순하게 하나의 label, class로만 갖는 것이 아니라 각각의 pixel들이 이미지 속 특정 객체의 영역을 가져 구조화 되는 것을 의미합니다.)
논문에서는 추가적인 기계학습적 요소없이 end-to-end로 모델을 학습하고 semantic segmentation에서 SOTA(state-of-the-art)를 뛰어 넘었습니다. 그리고 (1) pixelwise prediction과 supervised pre-training를 위한 end-to-end로 모델을 학습하는 것을 처음 시도하였습니다. 존재하는 여러 network들의 fully convolutional version들은 임의의 input 사이즈에 대해서 학습을 가능하게 합니다.
이전 연구들과 다르게 이미지 전처리, 후처리 과정이 필요하지 않습니다. 모델은 최근 성공한 모델들에서 그들의 learned representations을 가져와 fully convolutional, fine-tuning를 하고, 이러한 classification network를 재해석하여 Dense prediction할 수 있도록 변환하였습니다 (see Figure 1).
2. Related work
논문에서는 semantic segmentation의 direct, dense prediction를 위해 기존 VGG, LeNet, AlexNet의 구조를 재구성하였습니다.
- Mantan et al. : 임의의 input size에 대한 convnet을 확장하는 아이디어가 처음 등장
- Wolf and Platt : CNN의 출력을 가져와 해당 출력을 사용하여 postal address block에 대한 감지 점수를 나타내는 2차원 맵을 생성
- Ning et al. : C.elegans(선충중 하나로 간단한 형태를 가진 다세포 생물) 조직의 대략적인 multiclass segmentation를 위한 Convnet을 Fully convolutional 추론으로 정의합니다.
Fully convolutional 연산은 많은 layer를 가지는 현대시대의 네트워크에도 많이 활동되었습니다.
- Sermanet : Sliding window detection
- Pinheiro and Collobert : Semantic segmentation
- Eigen et al. : image restoration
- Tompson et al. : End-to-end로 part detector, pose estimation을 위한 공간적 모델로서 학습시키기 위해 fully convolutional training을 드물게나마 효과적으로 활용했다.
- He et al. : feature 추출을 위해 classification nets의 non-convolutional 요소들을 제거하였다.
각각의 자세한 방법들은 각각의 논문들을 참조하세요.
몇몇의 최신 연구들은 convnet들을 dense prediction problems들의 적용하였다. 그리고 아래의 요소들을 포함시켰습니다.
- small models restricting capacity and receptive fields
- patchwise tranining
- post-processing(superpixel projection, random field regularization, filtering, etc.)
- input shifting and output interlacing for dense output
- multi-scale pyramid processing
- saturating tanh nonlinearities
- ensembles
위에서 언급한 machinery들이 없이도 supervised pre-training과 fully convolutionally을 fine-tune함으로써 image classification을 사용하고 이런 deep classification nets을 확장함으로서 whole image inputs과 whole image ground thruths을 보다 더 쉽고 효율적으로 학습할 수 있었습니다.
3. Fully convolutional networks
Convnet의 convolution, pooling, activation function들 덕분에 translation invariance 성질을 가지게 됩니다.
독립적으로 patch-by-patch로 연산하는 것보다 전체 이미지에 대해서 layer-by-layer로 학습을 하는 것이 feedforward, backpropagation에서 훨씯 더 효율적입니다.
Pixelwise prediction을 수행하기 위해서는 coarse한 출력을 다시 픽셀들에 연결해 주어야 합니다.
3.1. Adapting classifiers for dense prediction
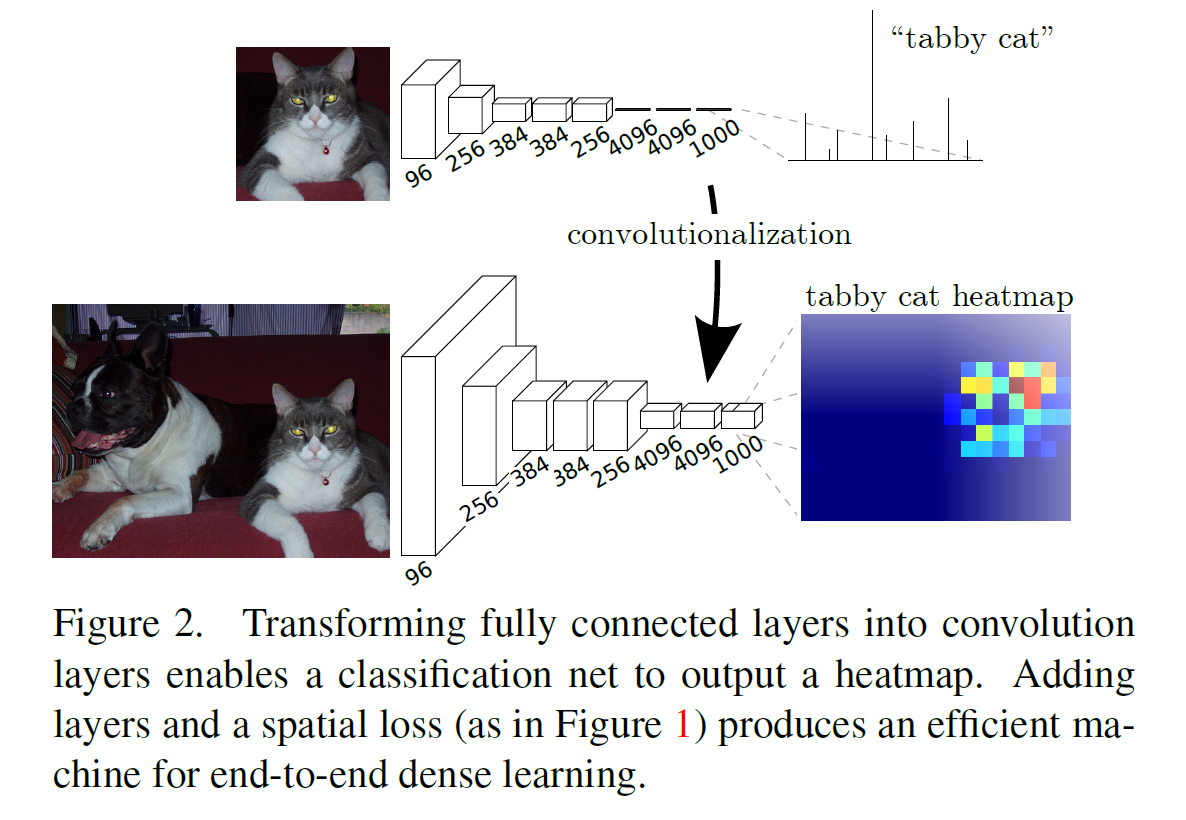
기존 recognition net들은 표면적으로는 고정된 input과 non-spatial한 output를 생성합니다. 이러한 net들의 fully connected layer들은 고정된 dimension들을 가지고 spatial coordinate들을 제거한다. 하지만 이런 fully connected layer들은 convolution으로서 kernel들과 함께 전체 이미지의 지역들을 커버하여 classification을 해준다. 따라서 이 네트워크들을 fully convolutional network로 변환함으로서 아무런 사이즈의 input를 받아올 수 있고, output으로 classification map을 가져올 수 있다(see Figure 2).
Fully convolutional net으로 만들어진 모델의 spatial output map들은 자연스럽게 semantic segmentation과 같은 dense problem들을 하게끔 선택된다. 모든 output cell에 대한 ground truth가 가능해짐에 따라 기존 방식처럼 전처리, 후처리, any machinery들이 필요 없기 때문에 forward와 backward pass들이 더 수월해진다.
3.2. Shift-and-stitch is filter rarefaction
논문에서 Input shift and output interlacing은 OverFeat 논문에서 소개된 interpolation없이 coarse output에서 dense prediction를 하는 트릭을 소개합니다.
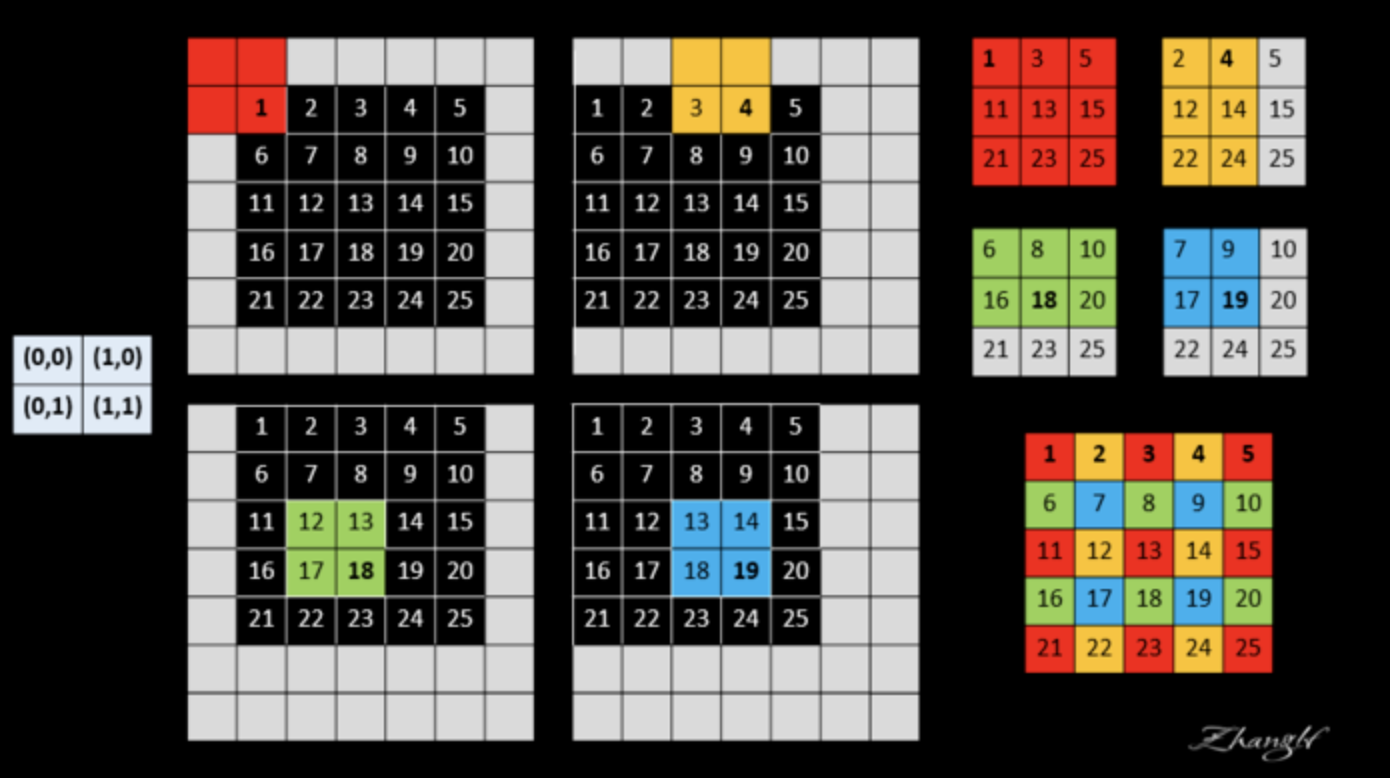
shift-and-stitch방식은 위 그림과 같이 ouput feature map에 위치를 움직이고 그때 max pooling를 사용하여 위치의 변화에 따른 각각의 max 값들을 저장하고 저장된 max값들을 위치에 맞게 다시 재배열하여 upsampling하는 트릭입니다.
하지만 위와 같은 방식은 receptive field를 작게하면 오랜 연산시간이 필요하며 filter들은 fine한 정보만을 보게 됩니다.
따라서 논문에서는 다음의 연산량을 해결하기 위한 trick를 소개합니다.
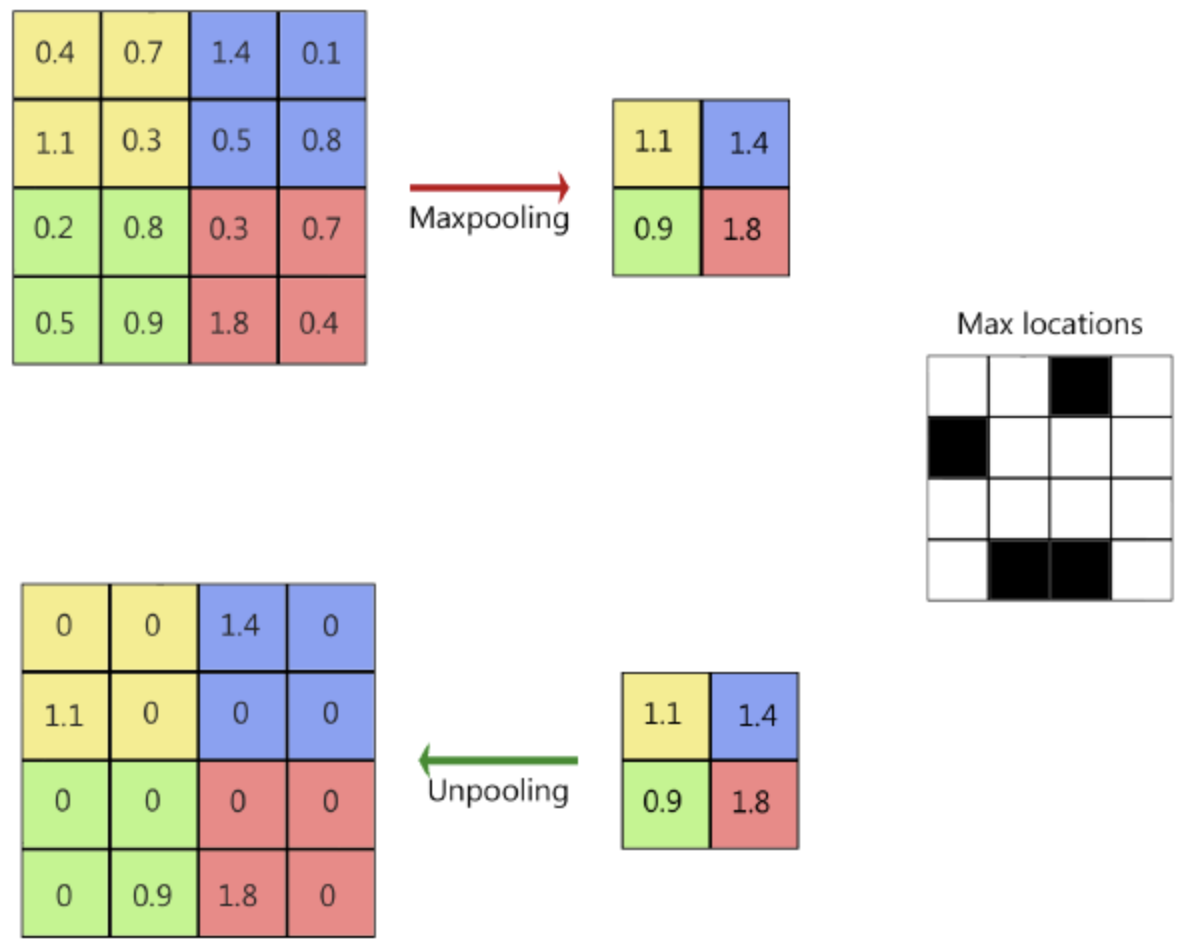
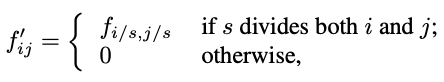
위 그림의 방법은 한번의 feature map에 대한 pooling을 진행하고 나온 값들을 위치정보와 같이 저장한 뒤 식에 나온 것처럼 i/s, j/s가 나눠 떨어지면 해당 max값을 넣고 아니면 0으로 값을 채우면 shift-and-stitch와 비슷한 효과를 낼 수 있습니다.
비록 receptive field size를 감소시키는 것 없이 ouput를 촘촘하게 만들 수 있지만 결국 위와 같은 방식은 filter들이 기존 방식처럼 fine한 정보에 접근하는 것이 제한되는 문제가 발생하게 됩니다.
논문에서는 skip layer fusion이 더 효과적이기 때문에 위와 같은 방식들은 사용하지 않는다고 말합니다.
3.3. Upsampling is backwards strided convolution
coarse output를 dense pixel에 연결하는 다른 방법은 바로 interpolation입니다.
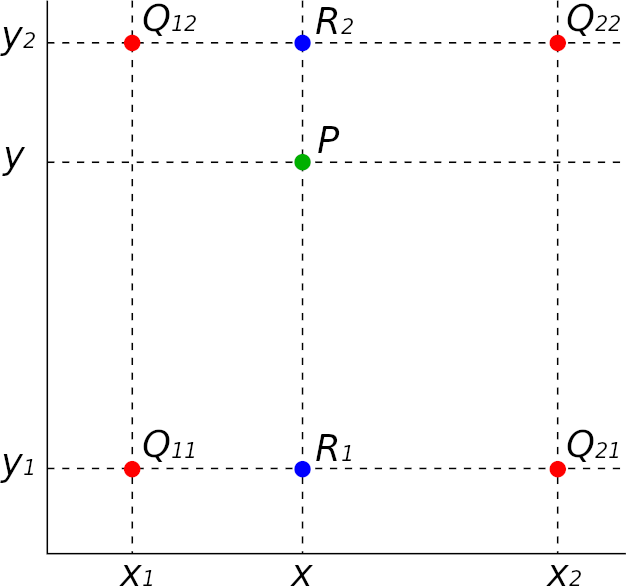
Bilinear interpolation은 주어진 네 개의 이웃 값을 사용하여 새로운 값을 추정하는 기술 중 하나입니다.
- 가로 방향으로 p의 x좌표는 x1, x2 사이의 상대적 위치에 따라 linear interpolation를 수행합니다.
- 세로 방향으로 p의 y좌표는 y1, y2 사이의 상대적 위치에 따라 linear interpolation를 수행합니다.
- 그렇게 얻은 두 값을 bilinear interpolation를 수행하여 최종 결과를 얻습니다.
이 과정을 통해 주어진 네 개의 이웃 값을 사용하여 주변 픽셀 사이의 값을 부드럽게 추정할 수 있다.
하지만 논문에서는 이러한 선형 기법들을 사용하지 않고 transposed convolution를 사용 하여 upsampling을 진행함니다.
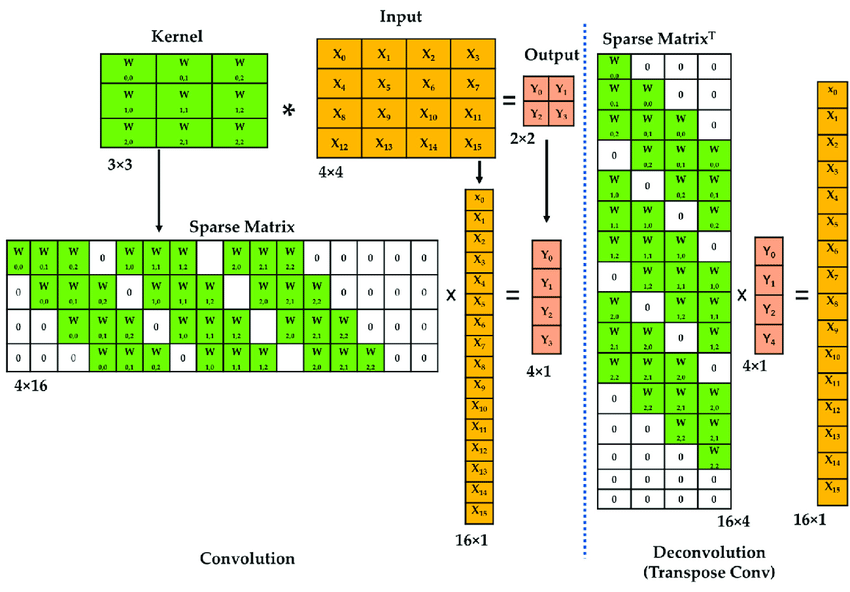
Transposed cconvolution(Deconvolution)은 사진과 같이 upsampling과정에서 기존 kernel matrix를 transpose시켜 convolution과정에서 나온 feature map과 행렬곱을 하여 upsampling하는 방법입니다.
논문에서는 이러한 방식을 통해 pixelwise loss로부터 backpropagation을 통해 end-to-end 학습을 진행할 수 있고, deconvolution layer와 activation layer들을 쌓음으로서 nonlinear한 upsampling에서도 학습이 가능해기 때문에 더 효율적이고, 더 빠르다고 주장합니다.
3.4. Patchwise training is loss sampling
논문에서는 하나의 이미지로 부터 나온 배치들의 loss들은 결국 receptivce field에 의해 원본 이미지의 대한 값들을 포함하고 있기 때문에 Whole image fully convolutional training과 동일하다고 말하고 있습니다. 또한 여러번에 backward pass들을 지나다 보면 자연스럽게 batch들이 patch들의 정보들을 포함하게 된다고 말합니다.
물론 patchwise training을 통해 class imbalance문제들을 해결할 수는 있지만, 각 patch들 사이의 상관관계가 약해질 수 있습니다. 하지만 fully convolutional training에서 loss값들을 class별 비율로 차등 계산 (예를 들어 강아지 클래스가 고양이 클래스보다 10배 더 많다면 loss를 구할때 고양이에 대한 loss값은 10배를 강하게 주어서 강아지쪽으로만 학습이 되는 것을 완화시킬 수 있다.) 을 통해 class imbalance문제를 해결할 수 있고, whole image에 대한 학습이기 때문에 spatial correlation도 해결 할 수 있습니다.
Patchwise training도 해보았지만 dense prediction에서 빠르거나 더 나은 수렴을 보여주지 않았기 때문에 더 효율적인 whole image training을 논문에서는 사용하였습니다.
4. Segmentation Architecture
논문에서는 ILSVRC에서 좋은 성적을 낸 model들을 FCN으로 변경하고 upsampling과 pixelwise loss를 구하기 위해 기존 구조를 보강하였습니다. 그리고 coarse, semantic한 정보와 local, appearance한 정보들을 결합하기 위한 skip connection을 추가 합니다. per-pixel multinomial logisitc loss를 통해서 학습을 진행하고, background을 포함한 모든 클래스에 대한 standard metric을 통해서 모델을 평가하게 됩니다. 또한 ground truth에서 모호하거나 다른 픽셀들에 대해서는 모두 무시를 합니다.
4.1. From classifier to dense FCN
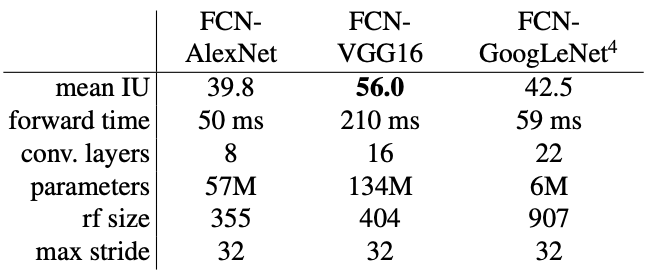
- VGG16에 경우에는 segmantic segmentation 문제에서 VGG19와 비슷한 성능을 보였다.
- PASCAl class들(background 포함)을 예측하기 위해 receptive field가 1x1이면서 PASCAL class개수인 21 dimension을 가지는 conv를 추가하였다.
- 해당 네트워크들의 fine-tuning은 합리적인 예측들을 달성하였다.
- FCN-VGG16은 validation datset에 대해서는 56.0 mean IU로 SOTA 모델을 달성하였다.
- GoogLeNet과 VGG16은 classficiation accuracy는 비슷하지만 segmentation에서는 VGG16이 능가한다.
4.2. Combining what and where
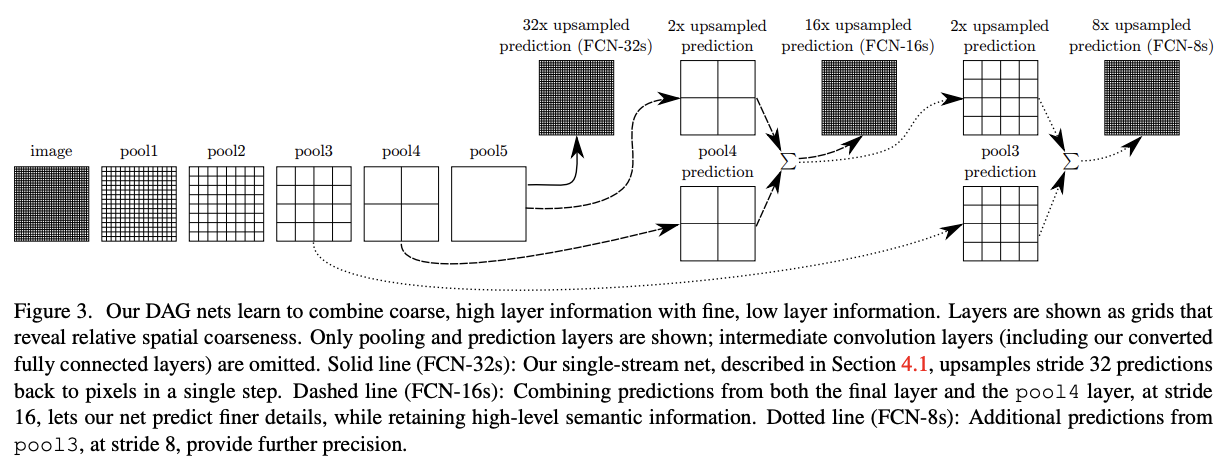
FCN-32s는 segmentation을 위해 fully convolutionalization을 하였지만 만족스러운 결과를 얻지 못하였습니다. 따라서 논문에서는 이 문제를 해결하기 위해서 prediction layer와 lower layer를 결합하는 skip connection를 도입하였습니다. 이를 통해 모델은 전반적인 이미지를 반영하면서 섬세하게 모델을 학습시켜 나아갈 수 있게 되었습니다.
Conv7에서 계산된 예측값을 bilinear interpolation으로 초기화된 x2 upsampling을 사용한 값과 pool4의 값과 더하였고, 이것을 pixelwise prediction을 하기 위해 x16 upsampling하였고, 이것을 FCN-18s라고 부릅니다.
FCN-16s는 end-to-end로 학습되었으며, 파라미터들은 FCN-32s의 parameters로 초기화되었습니다.
Conv7과 pool4의 더해진 값을 x2 upsampling한 후 pool3의 값과 더해서 x8 upsampling한 모델은 FCN-8s라고 부릅니다. 이를 통해 약간의 개선효과를 볼 수 있었습니다.
그 이하의 레이어도 위와 같은 방식으로 결합을 해보았지만 큰 개선 효과가 나타나지 않았기 때문에 더 이상의 lower layers과 결합을 진행하지는 않았다고 합니다. 또한 even finer predictions을 하기 위해 pool5에 더 작은 filter을 사용해 보았지만 더 나은 성능이 나오지 않았다고 합니다.
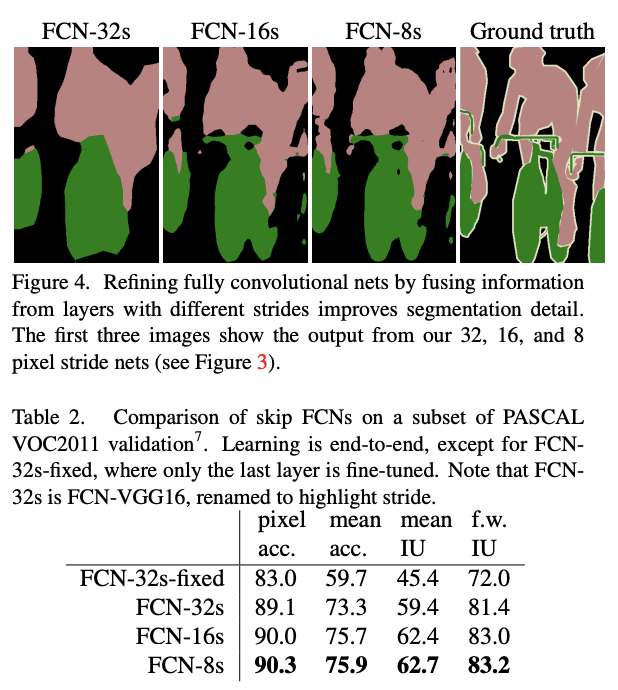
위 결과를 보면 확실히 FCN-8s가 나머지 두 모델의 비해 확실히 더 디테일하게 segmentation하는 것을 볼 수 있습니다. 또한 standard metrix에서도 더 좋은 성능을 보여줍니다. 하지만 FCN-18s에 비해서는 FCN-8s와 비교했을때보다는 드라마틱한 변화는 없는 것 같습니다.
4.3. Experimental framework
Optimizier
- SGD with momentum (momentum=0.9)
- minibatch size : 20
- learning rate : $10^{-3},\, 10^{-4},\, 5^{-5}$ for FCN-AlexNet, FCN-VGG16, FCN-GooLeNet, respectively
- weight decay : $5^{-4}$ or $2^{-4}$
Fine-tuning
Output classifier만 미세조정하는 것은 전체 네트워크에 대해 미세 조정하는 것에 비해 성능이 70%밖에 나오지 않기 때문에 논문에서는 전체 네트워크에 대해서 Fine-tuning을 하게 됩니다. 또한 아예 처음부터 모든 파라미터들을 학습시키는 것이 아니라 VGG16에 대해서 transfer learning을 하여 학습을 진행하였습니다.
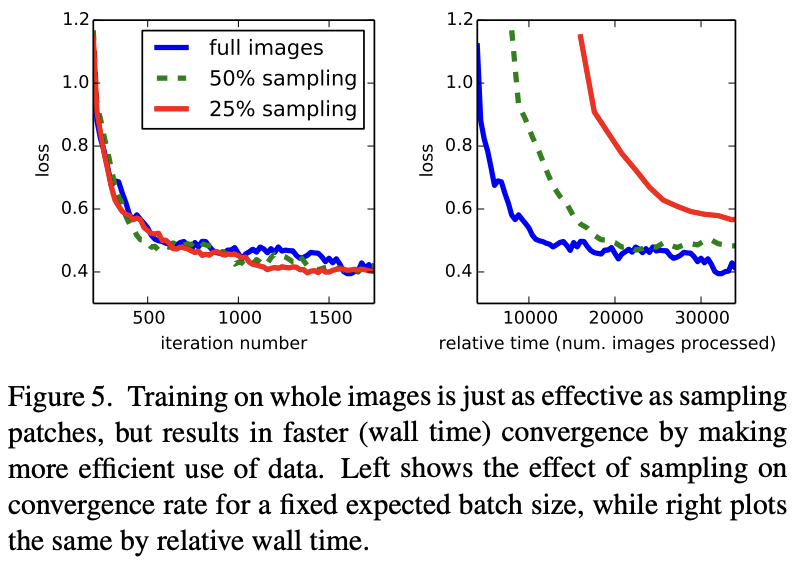
위에 그래프를 보면 아시다시피 비록 이미지 처리 속도 측면에서는 sampling하는 것이 조금 더 빠르지만 실질적인 모델의 convergence rate에서는 거의 아무런 차이가 없기 때문에 해당 논문에서는 전체 이미지로 모델을 학습시켰습니다.
5. Results


사진을 보면 이전 SOTA 모델이였던 SDS보다 standard metrix가 더 높고 실제로 ouput 결과물들을 보면 FCN-8s가 더 segmentation을 잘한 것을 확인 할 수 있습니다.
Conclusion
이번 논문에서는 기존 Fully connected layer를 모두 Fully convolutional layer로 변경하였고, 그로 인해 전체 이미지에 대해서 pixelwise prediction이 가능하도록 하였습니다. 또한 transfer learning을 통해서 기존 base net의 pretrainded된 모델의 파라미터를 사용함으로써 모델을 보다 효율적으로 학습하였고, skip connection를 사용하여 모델이 coarse한 정보와 fine한 정보를 가지고 보다 더 좋은 성능을 이끌어 낼 수 있게 해주었습니다.