딥러닝 - FLOPs와 모델 최적화(Model Optimization)
FLOPs란
FLOPs란 Floating Point Operations의 약자로, 초당 수행되는 부동 소수점 연산의 양을 나타내는 지표입니다. 쉽게 말하면 딥러닝에서 모델이 순전파(Forward-Propagation)를 진행할때 곱셈, 나눗셈, 덧셈, 뺄셈등을 얼마나 많이 사용하는지 나타내는 지표입니다. 따라서 우리는 모델의 FLOPs를 알 수 있다면 모델을 더 나은 성능을 발휘하고 추론하는 최적화된 모델을 설계할 수 있게 됩니다. 하지만 우리는 FLOPs를 측정하기 위해서는 FLOP, FMA, MACs를 알아야 합니다.
FLOPS
FLOPS는 Floating Point Operations per Second의 약자이며 마지막 S가 대문자입니다. 그리고 이것은 하드웨어가 얼마나 좋은 성능을 가지고 있는지 알려주는 줍니다. 따라서 FLOPS가 크면 클수록 초당 하드웨어가 처리 할 수 있는 작업이 많다는 것이고, 이것은 추론 속도의 향상으로 이어지게 됩니다.
FMA
FMA는 Floating point Multiply and Add operation의 약자로, 특히 그래픽 처리 장치(GPU)와 같은 하드웨어에서 고성능 연산을 수행하는 것으로, FMA는 A*x + B를 하나의 연산으로 처리합니다.
MACs
MAC는 Multiply-Accumulate Computations의 약자로, FMA가 모델에서 몇번 실행되었는지 계산하는 것이 바로 MAC입니다. 하지만 FLOPs는 FMA에 있는 2개의 연산(곱하기, 더하기)를 별개로 취급하기 때문에 결국 MAC : FLOPs = 1 : 2 비율을 가지게 됩니다. 따라서 FLOPs를 계산할때는 MACs의 곱하기 2를 해주면 됩니다.
Rule of FLOPs in a model
- Convolutions - FLOPs = 2 x Number of Kernel x Kernel Shape x Output Shape
- Fully Connected Layers - FLOPs = 2 x Input Size x Output Size
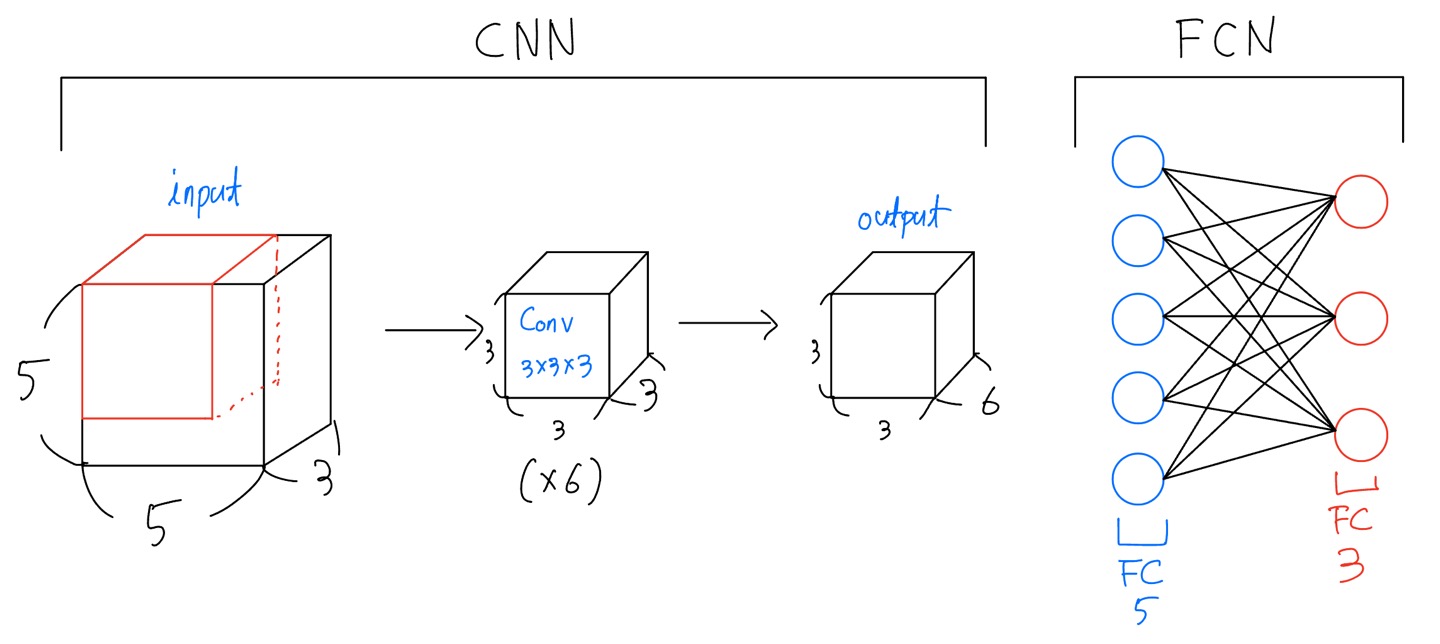
Convolution의 경우에는 그림에서 3x3 filter가 ouput shape만큼 input에서 FMA연산이 이루어지고, 이러한 연산이 kernel의 개수만큼 연산되기 때문에 위와 같은 식을 가지게 됩니다. FCN도 마찬가지로 FMA 연산이 이루어 지는 것은 input layer와 output layer 사이의 검은 선의 개수만큼 연산이 이루어 지기 때문에 마찬가지로 위와 같은 공식이 성립하게 됩니다. 그리고 앞에 2를 곱하는 이유는 앞서 언급했듯이 MAC와 달리 FLOPs는 FMA에서 곱하기 더하기 각각 계산하기 때문에 앞에 x2를 해주는 것입니다.
위의 그림의 FLOPs의 결과는
- CNN - 2x6x(3x3x3)x3x3 = 2,916
- FCN - 2x5x3 = 30
모델의 FLOPs 계산방법
- 입력이미지는 28x28x1(Gray scale)입니다.
- (3x3)사이즈의 커널을 2번 사용합니다.
- FCN에는 128개의 뉴런들을 사용합니다.
- MNIST Classification task이기 때문에 ouput layer의 unit수는 10개(0~9)가 됩니다.
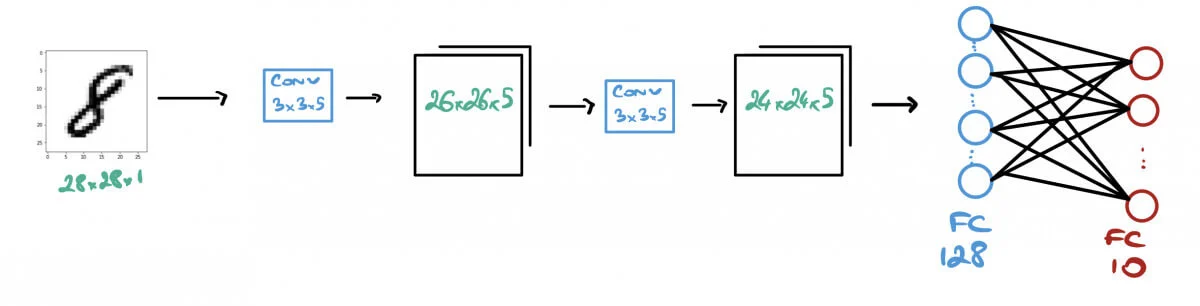
해당 모델에서의 FLOPs를 구하면 다음과 같다.
- First Convolution - 2x5x(3x3)x26x26 = 60,840 FLOPs
- Second Convolution - 2x5x(3x3x5)x24x24 = 259,200 FLOPs
- First FC Layer - 2x(24x24x5)x128 = 737,280
- Second FC Layer - 2x128x10 = 2,560 FLOPs
따라서 값들을 모두 더하면 FLOPs = 60,840 + 259,200 + 737,280 + 2,560 = 1,060,400 이라는 값이 나오게 됩니다.
따라서 만약 1G FLOPS를 수행하는 GPU가 있다고 가정하면 우리는 위에서 구한 FLOPs/FLOPS를 통해서 $\frac{1,060,400}{1,000,000,000} = 1ms$을 얻을 수 있습니다.
모델 최적화(Model Optimization)
우리는 위에서 지금까지 FLOPs를 구해보면서 모델의 대략적인 성능을 계산해 보았습니다. 그러면 지금부터는 어떻게 하면 모델의 연산 수를 줄여 보다 모델을 최적화 할 수 있는지 알아보겠습니다.
Pooling
첫번째 방법은 Pooling를 사용하는 것입니다. 아래 사진은 Pooling이 작동하는 방식으로 해당 Pooling를 사용하게 되면 이로 인해 Feature map의 공간적 차원이 downsampling되어 그로 인한 연산량의 감소로 FLOPs도 감소하게 됩니다.
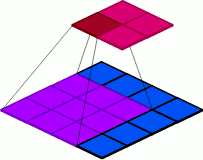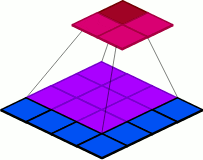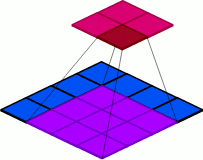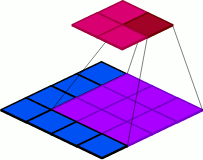
따라서 FLOPs를 줄이기 위해 Pooling을 사용하는 것은 좋은 방법이 될 수 있지만 여전히 문제점을 가지고 있습니다. 첫번째는 정보 손실을 초래할 수 있습니다. Maxpooling의 경우에는 오로지 가장 큰 값만을 남겨두기 때문에 작은 값들의 디테일이 무시될 수 있습니다. 또한 FLOPs의 연산량을 줄이기 위해 Pooling을 너무 많이 사용하면 공간적 차원이 반복적으로 축소하게 되면서 정보 손실은 물론이고 기존의 공간적 구조가 상실될 수 있습니다.
Separable Convolutions
Separable Convolution에 대해서 설명하기 전에 우리는 우선 두개의 Convolution을 알아야 합니다. 첫번째는 Depthwise Convolution이고, 두번째는 Pointwise Convolution입니다. 그래서 처음에는 Depthwise Convolution을 실시한 후에 Pointwise Convolution연산을 수행하는 것이 Separable Convolution입니다.
다음은 Depthwise Convolution입니다. 그림에서 볼 수 있듯이 입력 데이터의 각 채널에 대해 별도 필터(filter)를 사용하여 연산을 수행하는 합성곱입니다. 채널마다 독립적으로 필터가 적용되기 때문에 입력 데이터의 채널 수와 출력 데이터의 채널 수가 동일합니다.
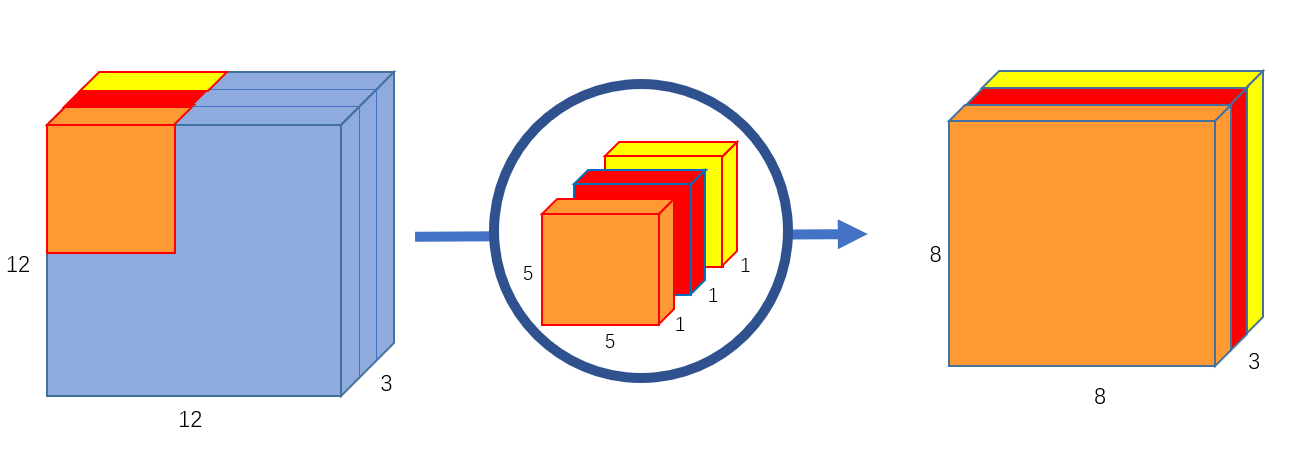
다음은 pointwise Convolution으로 사진과 같이 (1x1)크기의 필터를 사용하기 때문에 입력 데이터의 공간적 차원은 변화시키지 않고 채널의 수를 필터의 개수로 변경시킬 수 있습니다.
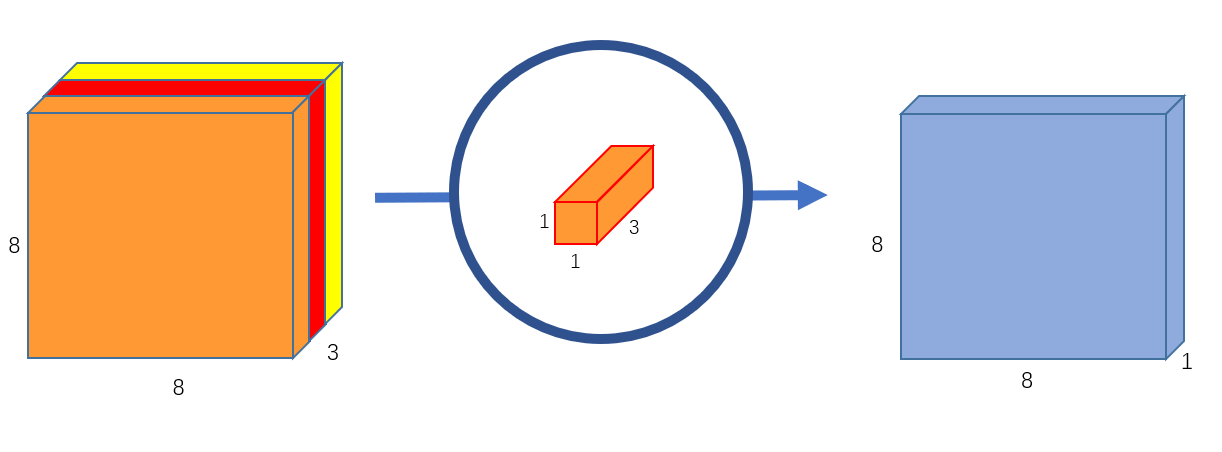
그러면 이제 Separable Convolutions를 사용하면 왜 FLOPs가 줄어드는지 알아보겠습니다.
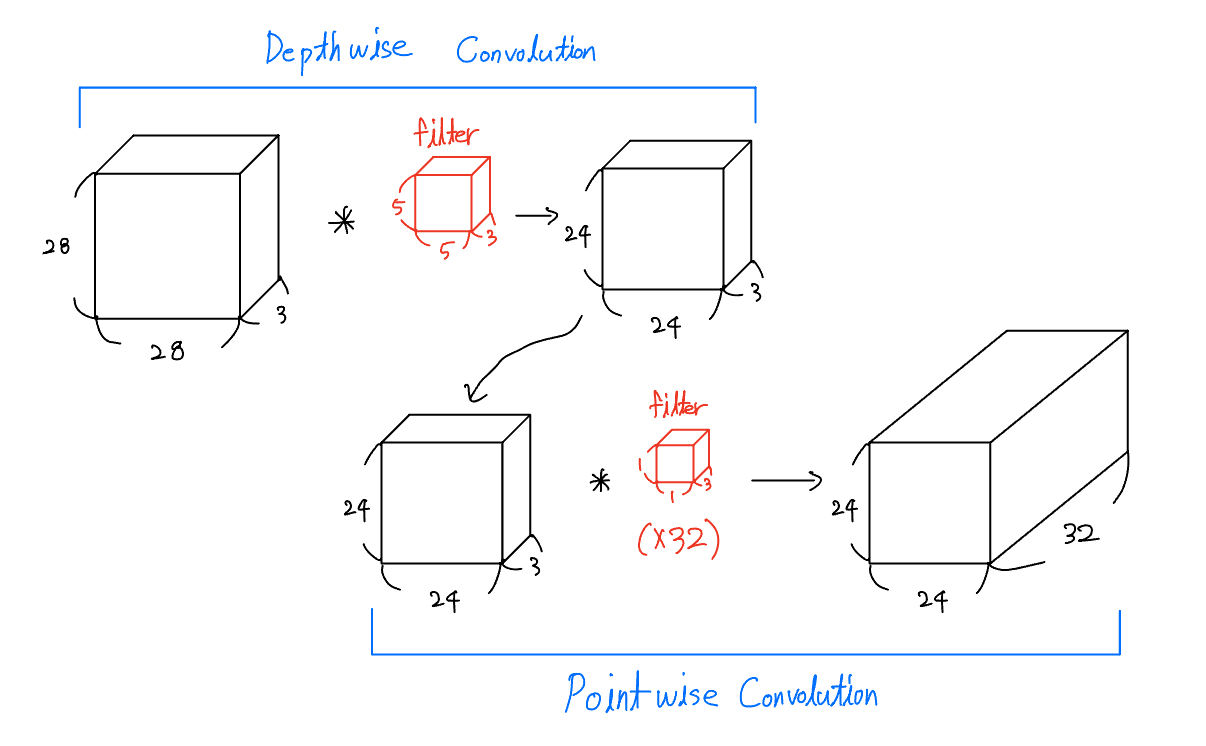
위에 Separable Convolutions를 계산하면 다음과 같습니다.
- Depthwise Convolution - 2x(5x5x3)x(24x24) = 86,400 FLOPs
- Pointwise Convolution - 2x32x(1x1x3)x(24x24) = 110,592 FLOPs
따라서 위해 두 값을 더하면 196,992 FLOPs가 나오게 됩니다.
그럼 이제 아래의 기존 Standard Convolution를 사용했을 때의 FLOPs를 구해보겠습니다.
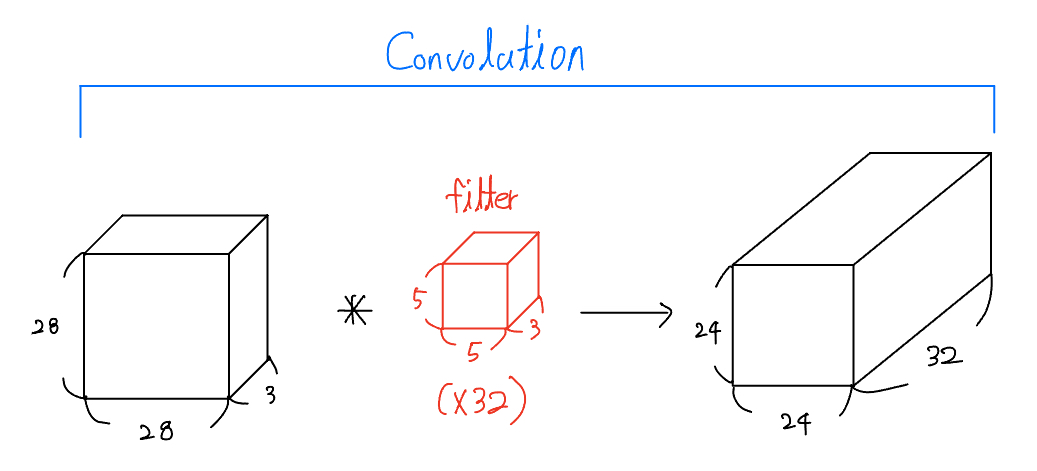
- Standard Convolution - 2x32x(5x5x3)x(24x24) = 2,764,800 FLOPs
위에 두개의 결과를 보면 한눈에 봐도 FLOPs의 차이가 많이 나는 것을 확인 할 수 있습니다. 따라서 Separable Convolutions는 모바일 및 경량 모델에서 많이 사용되고 있는 합성곱 연산의 한 종류입니다.
Model Pruning
Model Pruning는 딥러닝 모델에서 불필요한 가중치 및 연결을 제거하여 모델을 최적화하는 기술입니다. 모델의 학습이 완료된 후, 각 가중치의 중요도를 평가하게 됩니다. 일반적으로 중요도는 가중치의 절댓값에 기초하여 결정되며, 중요한 가중치는 보다 큰 값이 부여가 됩니다. 그후 중요도가 낮은 가중치는 제거하거나 0으로 설정하여 모델의 크기를 줄입니다. 이로써 모델은 FPP(Forward-Propagation)과정에서 보다 적은 연산을 수행하게 되어 모델을 경량화 또는 최적화 할 수 있게 됩니다.
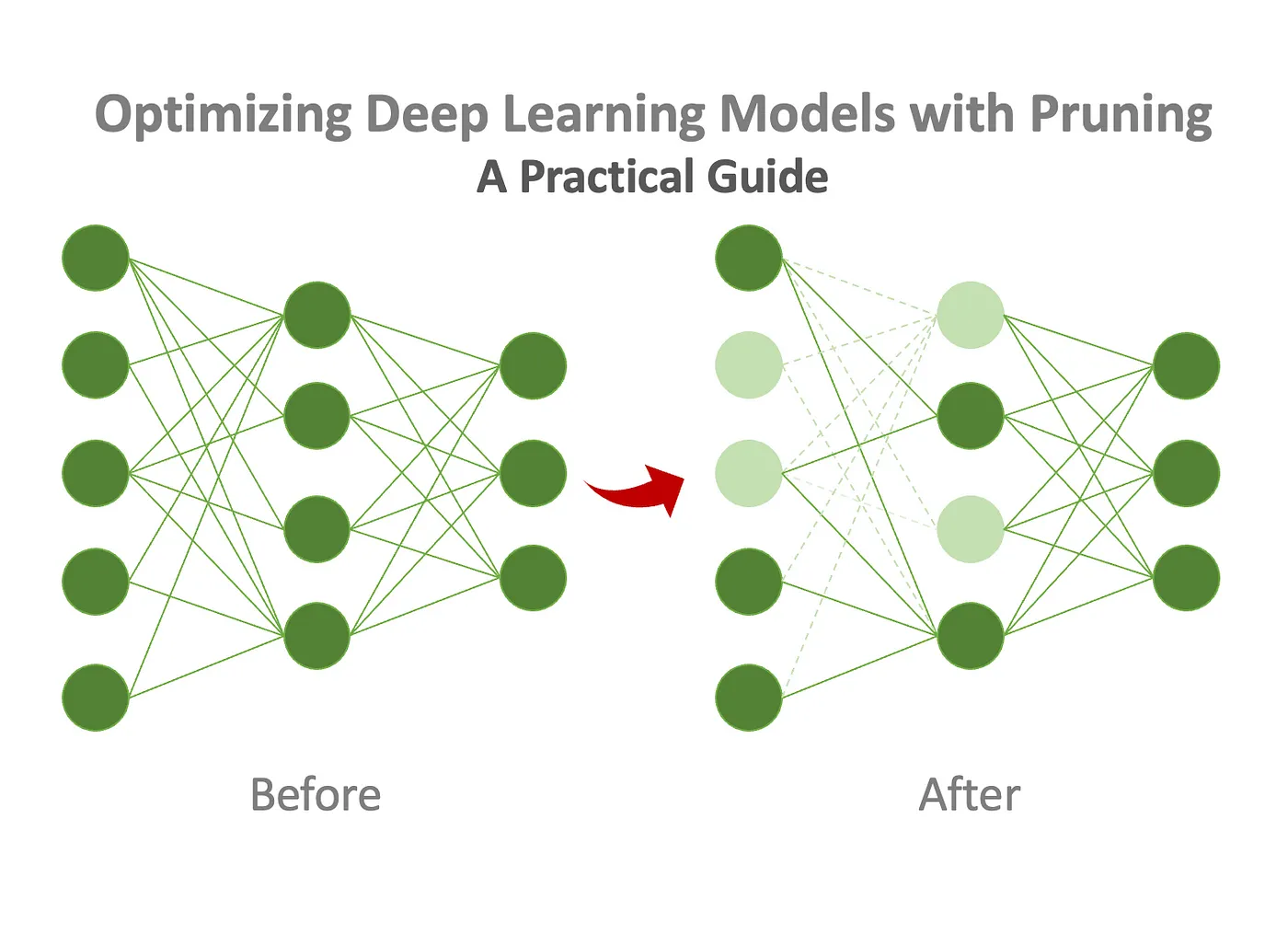
Dropout과 Model Pruning은 완전히 다른 기술입니다. Dropout는 모델이 학습과정에서 일부 뉴런을 randomly하게 끄는 것이고, Model Pruning은 학습이 끝난 후 가중치의 중요도를 매겨 향후 모델의 추론과정에서 중요도가 낮은 가중치를 제거하여 FPP과정에서 연산량을 줄이는 역활을 하는 것 입니다.