Paper Review - DenseNet(Densely Connected Convolutional Networks)
[Reference] CVPR2017 DenseNet Paper
Abstract
해당 논문은 Dense Convolutional Network(DenseNet)을 적용하여 각 층을 이후 모든 레이어로 연결하는 방식으로 모든 다른 층에 연결하는 신경망입니다.
각각의 레이어의 모든 이전 레이어의 feature map들을 input으로 사용되어 지고, 또한 그렇게 만들어진 output feature map도 이후 모든 레이어의 input으로 사용함으로서 몇가지 강력한 이점을 가집니다.
- Gradient vanishing issue를 완화시킬 수 있다.
- 강력한 feature들을 전파시킨다.
- Feature들을 재사용하도록 유도한다.
- Model parameters을 상당히 줄일 수 있다.
1. Introduction
CNN 모델들의 신경망이 깊어짐에 따라 gradient가 모델의 끝까지 도달하지 못하여 Vanishing gradient 문제들이 발생하였습니다. 이 문제를 ResNet, Highway Network는 하나의 층에서 다음 층으로 identity connections을 이용하여 신호를 우회시켜 해당 문제를 해결하였습니다.
비록 서로 다른 접근법들이 network의 구조나 학습 절차을 변화시켰지만, 기본적으로 그들은 모두 이전 레이어의 값을 이후 레이어의 short path로 연결한다는 것은 일치하였습니다.
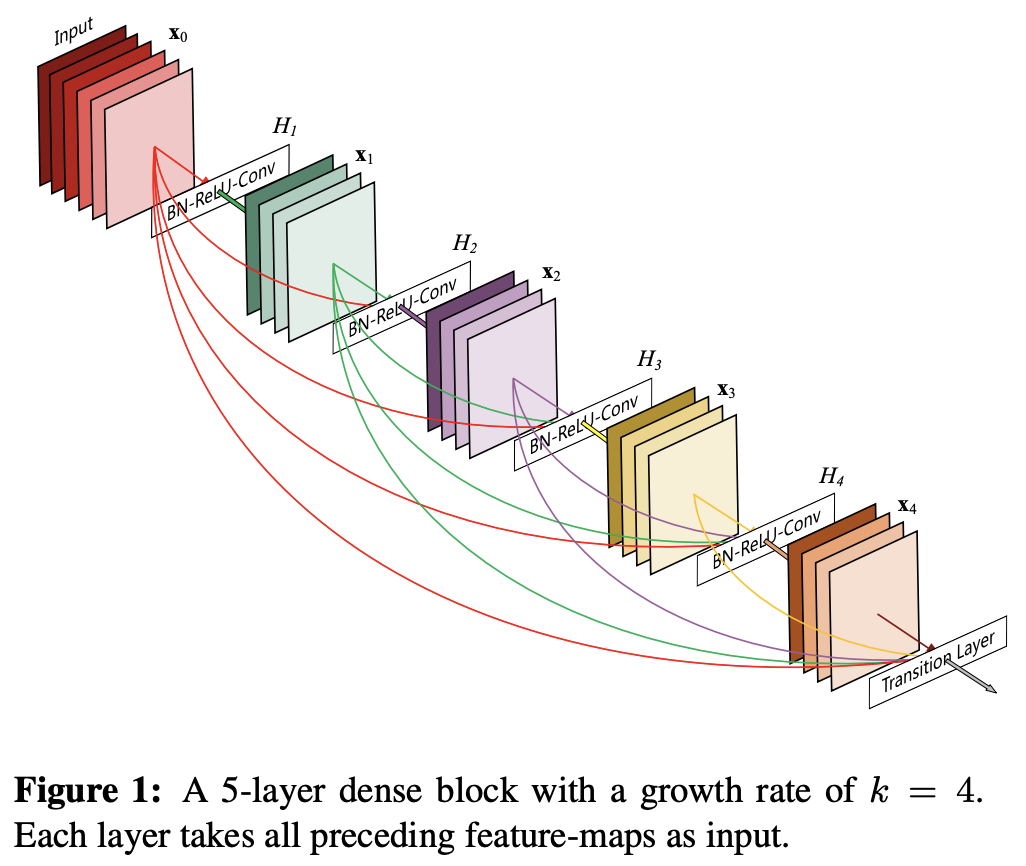
해당 논문에서는 maximum inforamtion을 네트워크의 모든 레이어 사이로 확실하게 흐르게 하기 위해서 feature map 사이즈을 일치시킨 상태로 모든 layers을 연결한다. 기존의 feed-forward을 유지하기 위해서 각각의 layer은 이전 모든 layers로부터 정보들을 얻고 자신의 정보또한 이후 모든 레이어들로 전달시킵니다 (see Figure 1).
ResNet과는 다르게 각각의 features을 summation하는 것이 아니라 concatenate를 진행한다. 만약 L개의 layer를 가지는 네트워크가 있다면 총 $\frac{L(L+1)}{2}$개의 connections을 가지게 됩니다.
이로인한 반직관적인 효과로는 DenseNet은 기존 전통적인 Convolutional network들과 다르게 더 적은 parameters을 사용합니다. 이유는 DenseNet layer들은 매우 narrow하기 때문입니다 (각각의 layer는 12개의 filter 개수를 가진다.). 따라서 Network의 collective knowledge에 오직 소수의 feature map만 추가하고 나머지 feature map은 변경하지 않고 유지하여, 모델은 명시적으로 network에 추가해야할 정보와 보존해야할 정보를 구별할 수 있게 되었습니다. 그렇게 final classifier는 모든 특징 맵을 기반으로 결정을 내릴 수 있게 됩니다.
Parameter 효율성 이외에도, DenseNet은 network을 통한 정보와 기울기의 흐름을 향상시켜 학습을 쉽게 만듭니다. 각각의 레이어는 모두 직접적으로 loss function, original input signal의 gradients에 접근하게 되면서 잠재적인 deep supervison의 역활을 수행하게 됩니다. 더 나아가 더 적은 training set size를 가지는 task들에 대해서 overfitting을 줄여주는 regularizing effect 또한 발견했다고 합니다.
2. Related Work
현대 네트워크들의 layer의 수가 증가함에 따라 Architecture간의 차이를 더욱 증폭시켰으며, 다양한 연결 패턴들을 연구할 수 있게 기여하였고, 동시에 이전의 연구들의 아이디어들도 다시금 주목받게 하였습니다.
- Cascade-Correlation Architecture : 논문에서 제안한 DenseNet 구조와 비슷하면서 1980년대에 neural network 학문에서 연구되어졌다.
- Highway Network : Gating units을 사용한 bypassing paths을 100개 이상의 layers를 가지면서 end-to-end로 모델을 효과적으로 학습하는 수단을 제공한 최초의 Architecture 중 하나.
- ResNet : 다양한 detection tasks에서 기록적인 performance을 보여주었고, Stochastic depth는 학습과정에서 randomly하게 layers을 drop하여 1202-layer에서도 fully train하게 만들었다. (이를 통해 논문에서는 deep (residual) network에서 많은 양의 중복들이 있기 때문에 무조건 모든 layer를 사용하거나 집중할 필요는 없다는 것을 보여준다고 말합니다.)
모델을 deeper하게 하는 완전히 다른 접근으로는 모델의 width을 증가시키는 방법이 있다.
- GoogLenet : 서로다른 사이즈의 filter들을 사용하여 만들어진 feature maps을 concatenate하는 “Inception module”을 사용하였다.
- FractalNet : 모델의 width를 증가시키는 wide network structure을 사용하여 몇몇 datasets에 대해서 경쟁력있는 결과를 이끌어 냈다.
서로다른 layers에서 학습된 feature-maps을 연결하는 것은 이후 layers의 input에 변화를 증가시켜 모델의 효율성을 향상시켰습니다.
- Inception Network : DenseNet처럼 feature maps을 concatenate하였지만, DenseNet이 더 간단하면서 동시에 효과적이다.
- Network in Network(NIN) : Convolutional layers안에 micro multi-layer perceptrons을 포함시켜 보다 더 복잡한 features을 추출한다.
- Deeply Supervised Network(DSN) : internal layers은 auxiliary classifier의 의해서 직접적으로 supervised하여 이전 layer에서 받은 기울기를 강화할 수 있다.
- Ladder Network : Autoencoder에 대한 lateral connection 사용
- Deeply-Fused Nets(DFNs) : 다른 base networks의 중간 layer들을 결합하여 향상된 정보 흐름을 발생시킨다.
3. DenseNets
- $x_{0}$ : Convolutional network을 통과하는 단일 이미지 값
- $H_{l}(\cdot)$ : Batch Normalization(BN), Rectified linear units(ReLU), Pooling or Convolution(Conv)이 포함된 행동 함수
- $x_{l}$ : $l^{th}$번째 layer의 output
ResNets
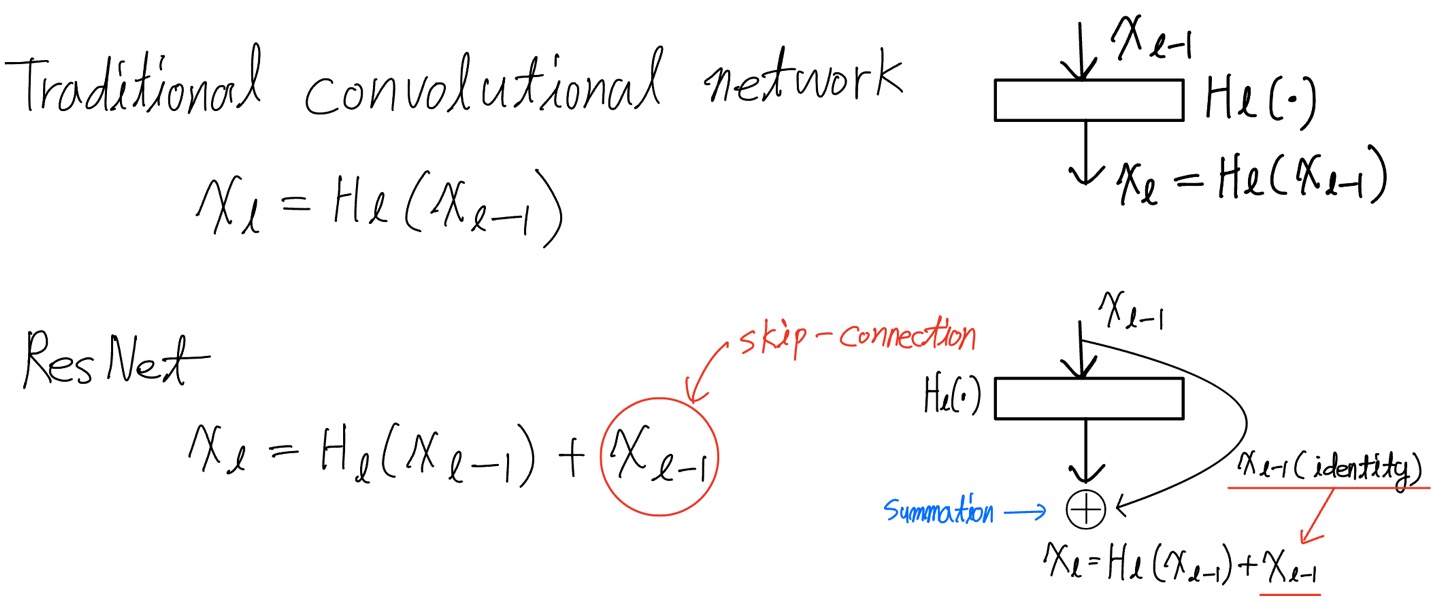
ResNet의 작동 방식은 위 사진과 같고 이를 통해 ResNet이 가지는 이점으로는 gradient가 나중 layer에서 이전의 레이어로 identity function을 통해 직접적으로 전달될 수 있게 도와준다는 것입니다. 하지만 ResNet은 그림에서 보시다 시피 summation을 사용하여 identity function과 $H_{l}$의 ouput을 결합하기 때문에 네트워크에서 정보의 흐름을 방해합니다.
Dense connectivity
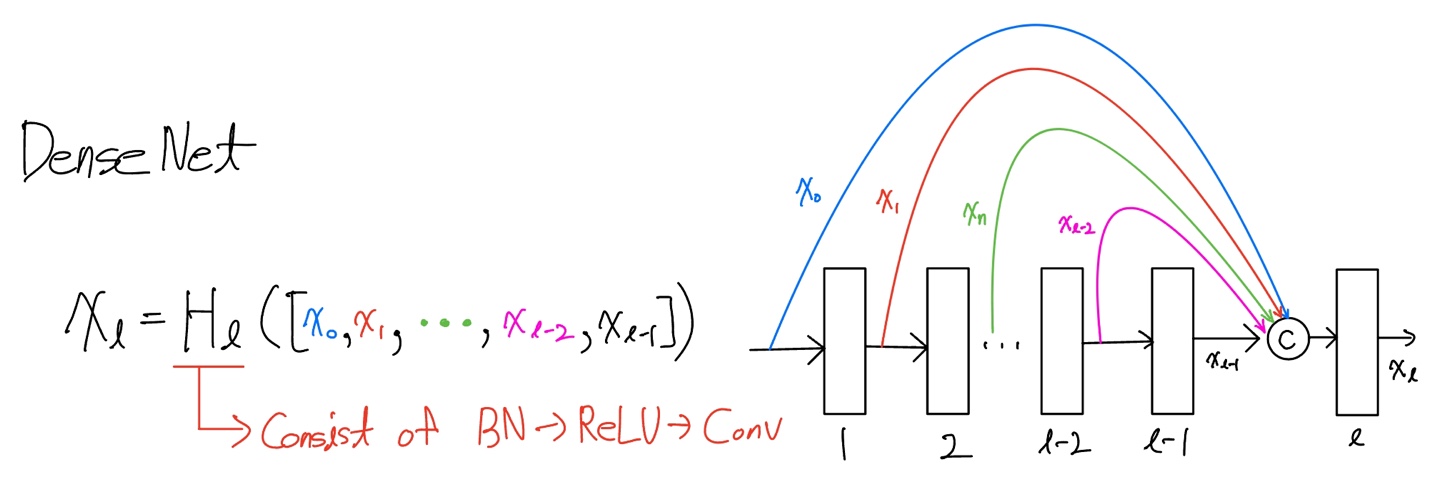
이전 모든 layer의 output feature map을 concatenate을 함으로써 layer와 layer 사이의 정보의 흐름을 더욱 향상시킬 수 있게 되었습니다. 그리고 이러한 network architecture을 DenseNet이라고 부릅니다.
Composite function
논문에서의 $H_{l}(\cdot)$의 값은 BN -> ReLU -> 3x3 Conv 순으로 정의되어 있는 함수입니다.
Pooling layers
Down-sampling은 convolutional network의 필수적인 부분입니다. 하지만 DenseNet은 feature map size가 바뀌면 안되기 때문에 사진에서 볼 수 있다시피 여러개의 dense blocks을 만들었고, denseblock 사이에는 transition layer을 만들어 주변 두개의 dense block들을 연결하였습니다.
- Transition layer 구성 : BatchNorm -> 1x1 Conv -> 2x2 Average pooling을 따르게 됩니다.
Growth rate
$k$을 사용하여 Dense Block내의 각각의 layer $H_{l}$의 feature map size을 $k$로 만들어서 일반적으로 늘어나는 feature map 사이즈를 깊어지지 않게 조절하여 보다 모델을 효율적이고 다른 현존하는 모델들보다 narrow하게 설계할 수 있게 됩니다. 따라서 위 Figure 1에서는 $k=4$로 설정하여 Dense Block를 구성한 것을 확인 할 수 있습니다.
Bottleneck layers
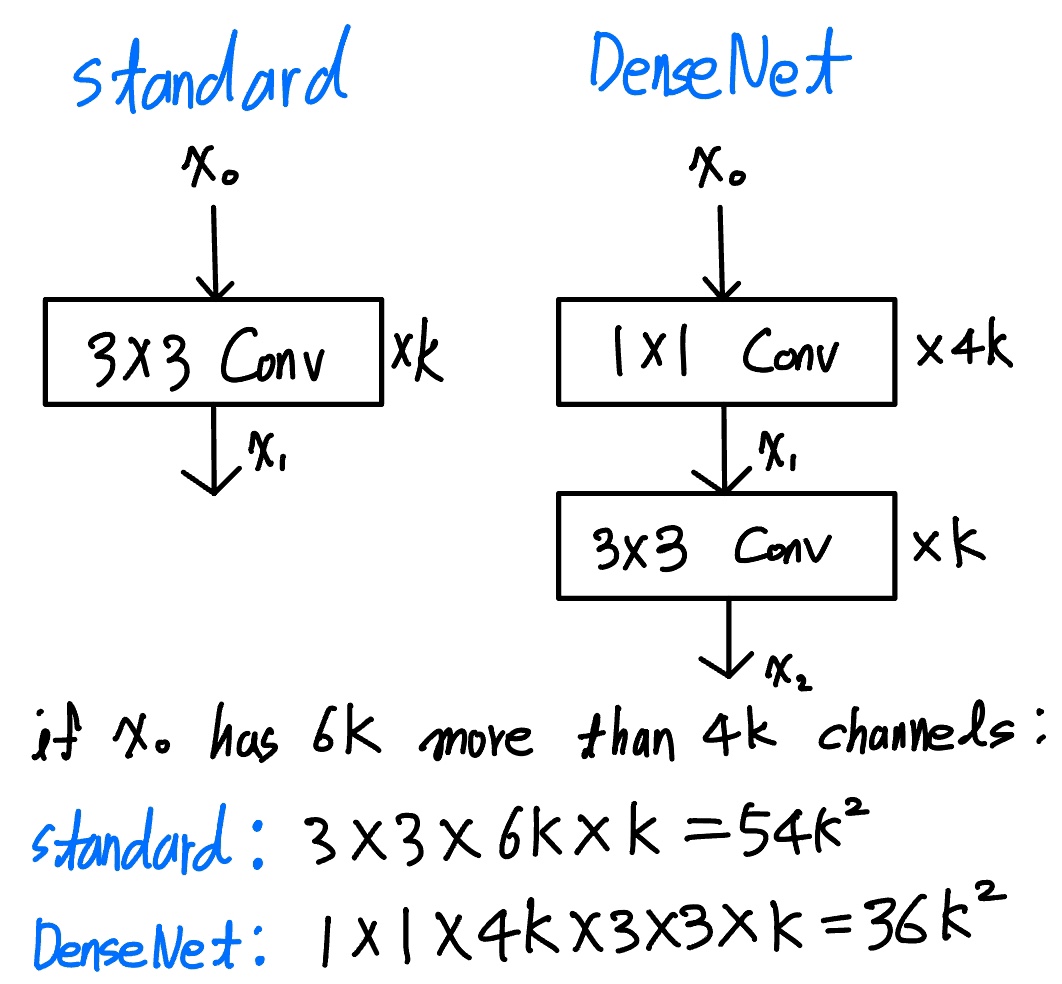
비록 각각의 layer들은 정해진 $k$개의 feature-maps을 생성하지만 DenseNet 구조상 input channel로 $n\times k$(n>4)인 경우의 데이터가 들어가기 때문에 1x1 Conv를 써서 $4k$만큼 줄여준 다음 3x3 Conv를 사용하여 $k$개의 feature-map을 생성하면 위 그림과 같이 trainable parameter의 수를 감소시켜 계산의 효율성을 증가시킬 수 있습니다. 또한 1x1 Conv를 앞에 하나 붙여줌으로 Non-linearity을 증가시켜주는 효과도 있습니다.
Compression
모델의 조밀함을 더욱 향상시키기 위해 transition layer에서 feature-map들의 숫자를 줄일 수 있습니다. $[\theta_{m}]$을 통해서 나타냅니다.
- $\theta<1$ : DenseNet-C (논문에서는 0.5로 설정)
- $\theta<1$, bottleneck 둘다 사용 : DenseNet-BC
* $\theta$을 조절함으로써 Dropout과 같이 regularization을 수행하여 overfiting을 예방하는 것 같습니다.
Implementation Details
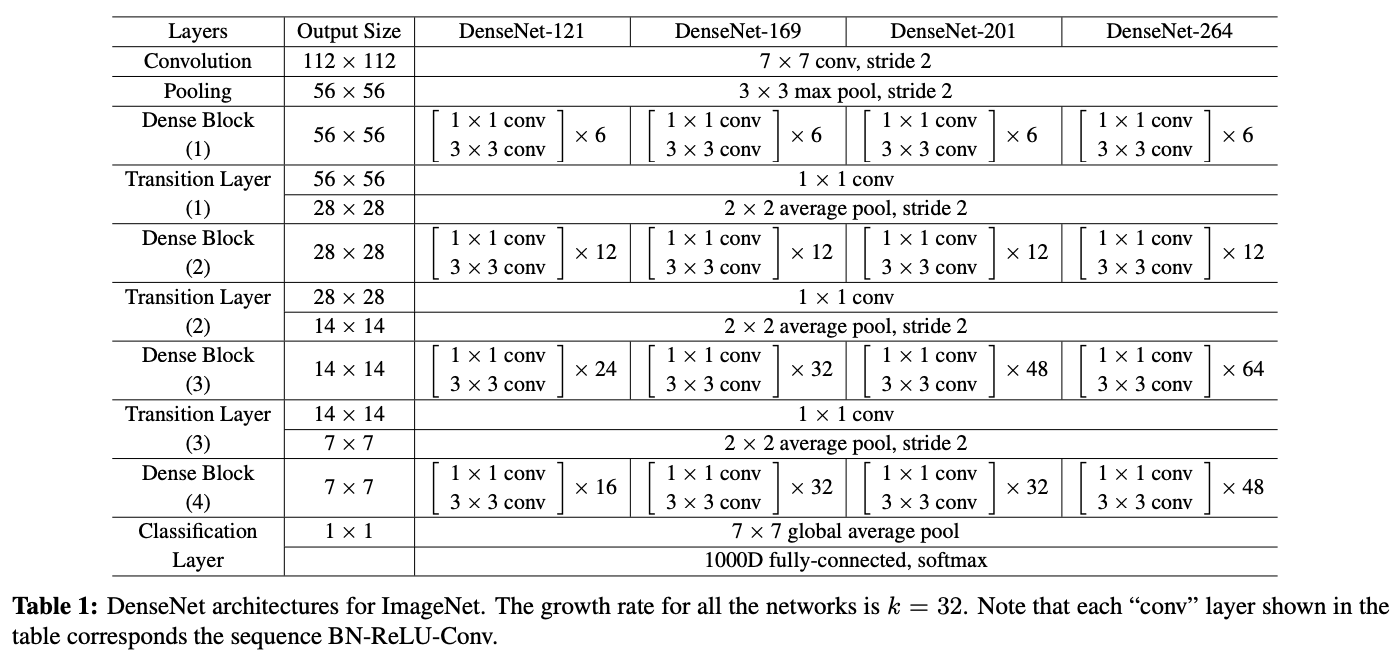
ImageNet에 대해서는 DenseNet-BC 구조를 채택하였고, 총 4개의 dense block에 224x224 input image을 사용하였습니다. 초기 convolution layer의 filter은 $2k$개를 가지면서, filter size는 7x7이고, stride은 2로 설정하였습니다. 그리고 이후 모든 layer의 feature-map의 사이즈는 $k$로 설정하였습니다.
4. Experiments
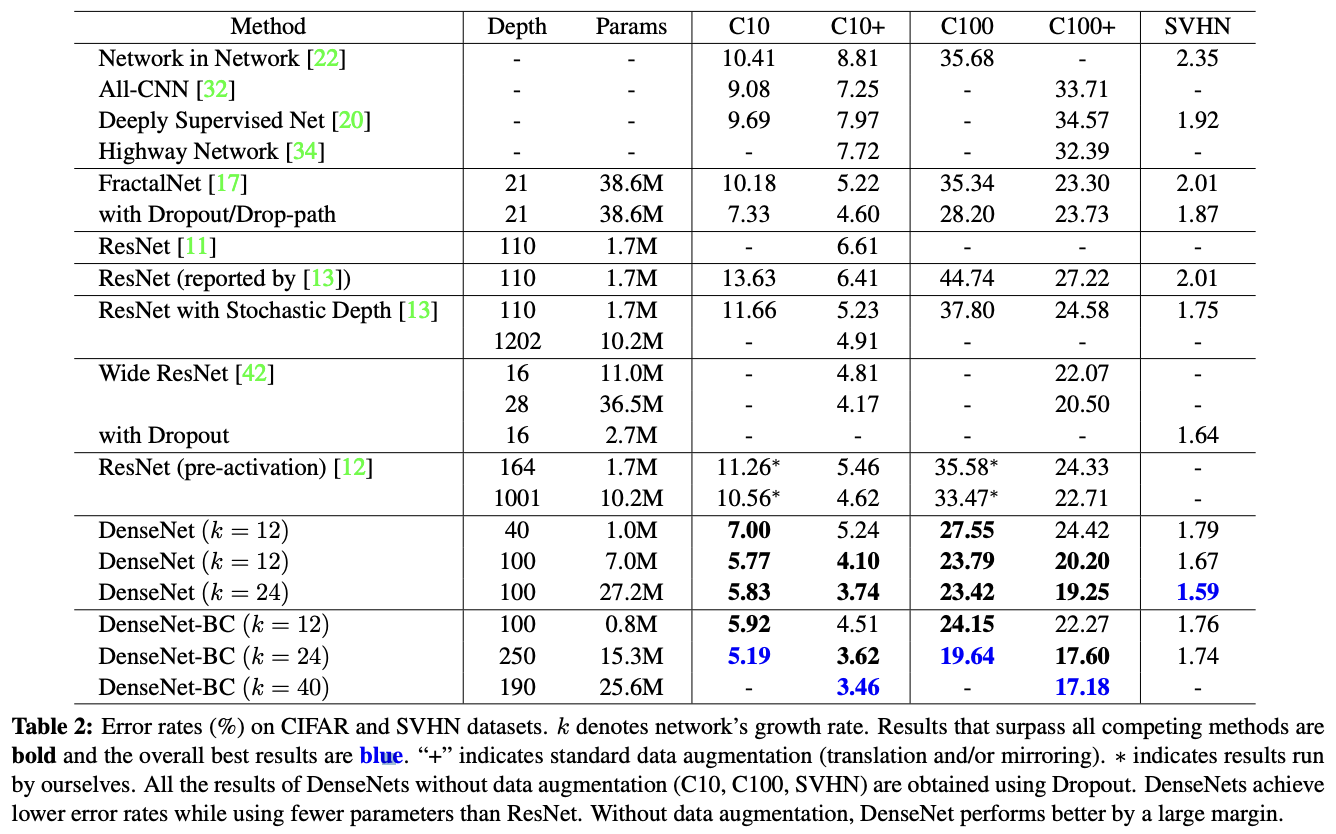
논문에서는 Resnet과 같은 다양한 SOTA Architectures와 여러가지 DenseNet의 변형들을 비교하여 실험하였습니다.
4.1 Datasets
CIFAR.
- C10 : 10개의 class을 가지는 CIFAR10
- C100 : 100개의 class을 가지는 CIFAR100
- C10+ : C10에서 범용적으로 사용되는 data augmentation을 사용
- C100+ : C100에서 범용적으로 사용되는 data augmentation을 사용
SVHN.
- SVHN에서는 아무런 data augmentation을 사용하지 않음
- 0~255 사이의 값을 가지는 pixel을 0~1로 Normalization을 수행
ImageNet.
- ResNet에서 사용한 data augmentation을 동일하게 적용
- Test을 할때는 single-crop 또는 10-crop을 적용
4.2 Training
- Optimizer : SGD
- CIFAR, SVHN은 모두 64 batch size을 가지고 각각 300, 40 epoch로 학습진행
- 초기 learning rate : 0.1(각각 전체 epoch의 50%, 75%에서 이전 learning rate의 $\frac{1}{10}$로 decay 진행)
- ImageNet에 대해서는 epoch은 90, batch size는 256
- ImageNet에 대한 learning rate은 0.1로 동일하지만 epoch 30, 60일때 10분의 1로 감소시킵니다.
4.3 Classification Results on CIFAR and SVHN
Accuracy.
Table 2을 보면 Table DenseNet-BC($L=190\,,k=40$)은 CIFAR dataset에서 최고의 성능을 보여주는 현존하는 모든 다른 모델들보다 더 뛰어난 성능을 보여주는 것을 확인할 수 있습니다. 그리도 더 흥미로운 것은 data augmentation이 진행되지 않은 C10, C100에서는 더 큰 차이의 나은 성능을 보여주는 것을 확인할 수 있습니다. 하지만 SVHN과 같은 단순한 문제에 대해서는 깊이가 길어지면 overfitting 문제가 발생하는 것을 확인할 수 있습니다.
Capacity.
Compression과 bottleneck이 없으면 $L, k$가 증가하면 모델의 성능도 나아진다는 것을 확인할 수 있습니다. 또한 DenseNet은 overfitting이나, 기존 ResNet이 가지는 optimization difficulties의 방해받지 않기 때문에 더 크고 더 깊은 모델에서 사용이 가능합니다.
Parameter Efficiency.
논문에서는 크게 두번의 비교를 통해서 파라미터 효율성을 설명합니다.
- FractalNet(38.6M), Wide ResNet(36.5M)에 비해 DenseNet-BC(15.3M)은 훨씬 적은 파라미터를 사용하면서 더 나은 성능을 보여주고 있습니다.
- DenseNet-BC(0.8M)은 pre-activation ResNet(10.2M)보다 90% 더 적은 파라미터를 사용하여 더 나은 결과를 도출하였습니다.
Overfitting.
DenseNet의 하나의 다른 장점은 바로 overfitting이 덜 발생하는 경향이 있다는 것입니다.
- C10, C100 column을 보면 21 layer을 가지는 FractalNet보다 깊이는 250 layer로 더 깊지만 error rates가 낮은 것을 통해서 증명하였습니다.
- 논문에서는 잠재적으로 overfitting을 일으키는 setting은 C10에서 $k$을 12에서 24로 올리면 이때 미미하게나마 error가 증가하는 것을 확인하였다고 말합니다.
Bottleneck으로 trainable parameter의 수를 감소시키고 계산의 효율성은 증가시켜주고, compression으로 복잡성은 감소시켜주었기 때문에 DenseNet-BC에서 overfitting을 효과적으로 대응할 수 있었습니다.
4.4. Classification Results on ImageNet
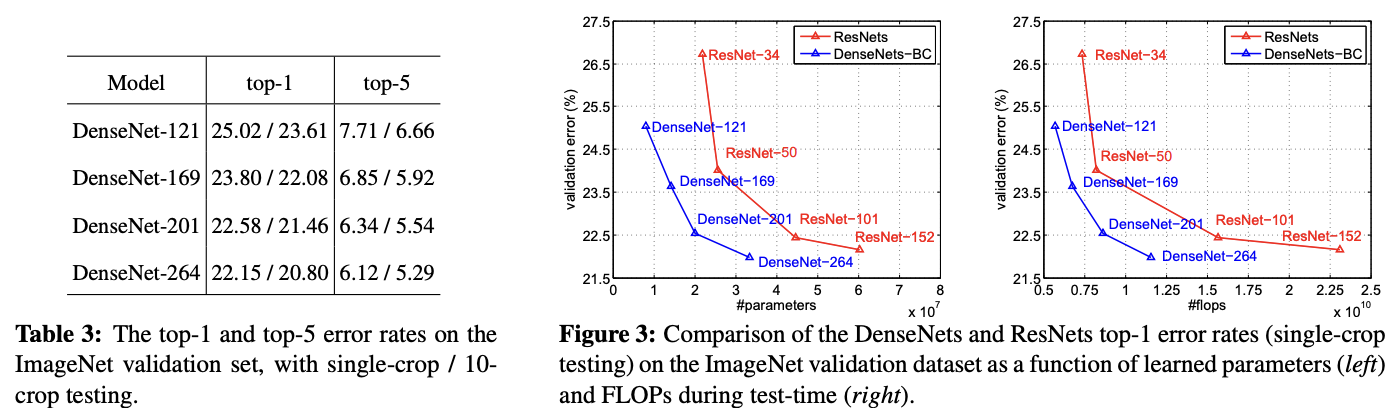
위 사진을 보면 DenseNet은 ResNet보다 더 적은 파라미터와 더 적은 계산량으로 더 좋은 성능을 보여줍니다. 예시를 들면 DenseNet-201은 ResNet-101과 비슷한 validation error값을 가지지만 parameter의 수는 20M이상 차이가 발생하고, 또한 Figure3의 오른쪽 그래프를 보면 ResNet-50이랑 연산속도가 비슷한 DenseNet-201은 ResNet-101보다 2배정도 더 빠른 연산속도를 가지고 있는 것을 확인할 수 있습니다.
FLOPs에 대한 자세한 설명은 아래 링크를 통해 확인할 수 있습니다. -> FLOPs와 모델 최적화
5. Discussion
표면적으로는 ResNet과 DenseNet은 매우 비슷합니다. DenseNet은 concatenate를 summation 대신 사용하였습니다. 하지만 이러한 작은 차이가 결국 앞서 설명한 많은 차이를 발생시켰다고 논문에서는 설명합니다.
Model compactness.
그어떤 DenseNet의 layer의 feature-maps도 이후에 모든 layer에 접근이 가능하기 때문에 모델의 재사용을 장려하여 모델을 더 컴펙트한 모델로 만들어줍니다. 이로인해 ResNet의 대략 $\frac{1}{3}$의 해당하는 parameter로도 DenseNet-BC는 비슷한 정확도를 이끌어 낼 수 있습니다.
Implicit Deep Supervision.
Dense convolutional netwrok의 향상된 정확도에 대한 하나의 설명은 shorter conncections을 통해서 loss 값을 모든 개별 layer에게 전달해주면서 추가적인 감독을 받기 때문이라고 논문에서는 설명합니다. 하나의 classifier은 많게는 2~3개의 transition layer을 통해서 모든 layer에게 direct supervision을 제공해줍니다.
Stochastic vs. deterministic connection.
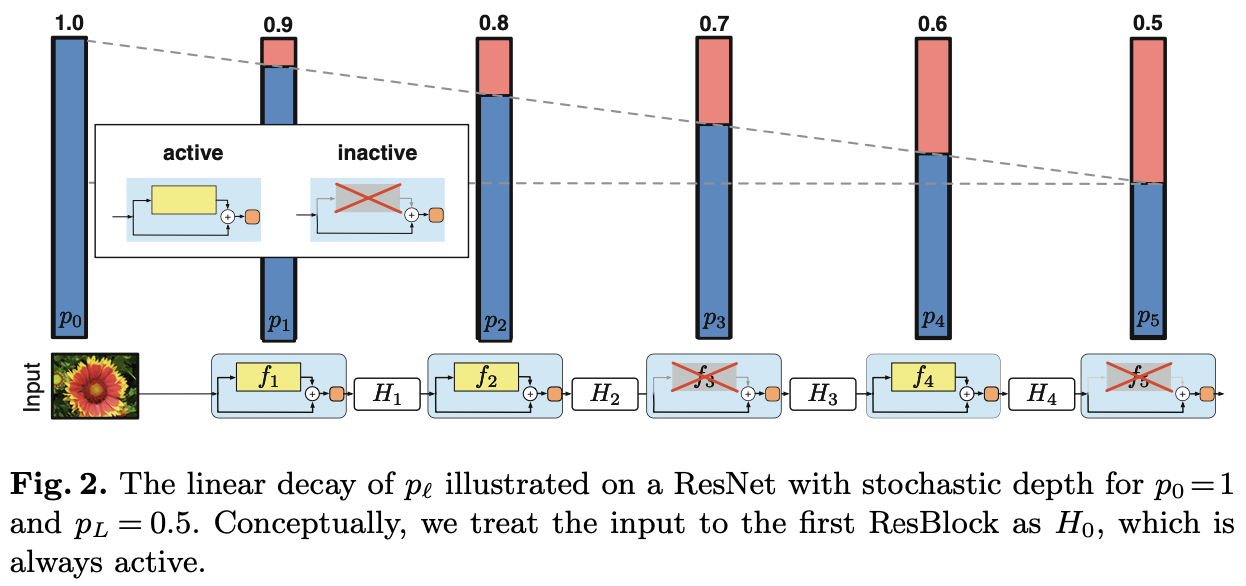
이해를 돕기 위해 위 사진은 ECCV 2016에서 발표된 Deep Networks with Stochastic Depth에서 가져온 사진입니다.
위 사진을 보시면 아시다시피 stochastic connection은 ramdomly하게 layer을 drop하게 되는데 이로인해 주변 레이어 간의 직접적인 연결을 생성하게 됩니다. 그리고 이때 pooling layer는 절대 drop되지 않기 때문에 DenseNet과 유사한 연결 패턴을 가지게 됩니다. 비록 방법은 궁극적으로 많이 다르지만, 그래도 stochastic connection을 가지는 ResNet은 기존 ResNet보다 성능이 좋기 때문에 이는 결국 해당 regularizer의 성공을 간접적으로나마 보여주게 됩니다.
Feature Reuse.
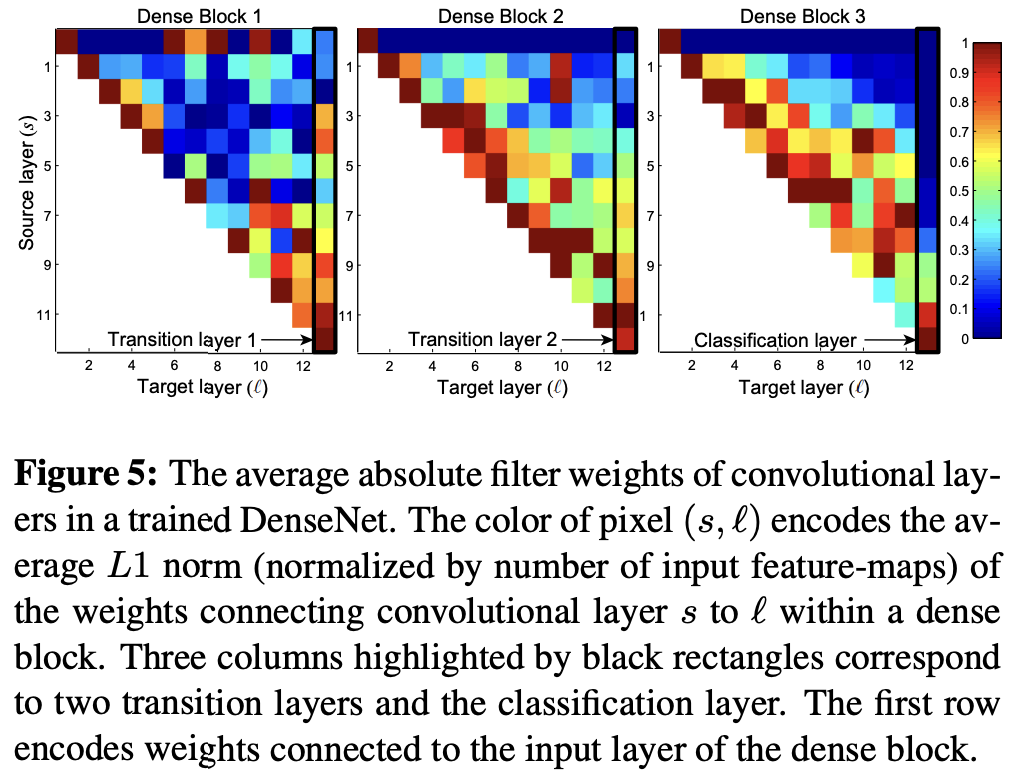
논문에서는 DenseNet이 각각의 layer의 preceding layers이 feature-maps에 잘 접근하는지를 확인하기 위해 블록 내의 각각의 convolution layer $l$에 대해서 layer s와의 연결에 할당된 평균(절대) 가중치를 계산하였습니다. 따라서 빨간색 점은 layer $l$이 평균적으로 $s$ layer에서 생성된 feature-map을 강력하게 사용했다는 것을 나타냅니다.
- 모튼 층은 동일한 Dense Block 내에서 많은 입력에 가중치를 분산시키는 것을 확인할 수 있습니다.
- Transition layer도 이전 Dense block내의 모든 층에 걸쳐 가중치를 분산시키며, DenseNet에서 첫번째 층에서 마지막 층으로의 정보 흐름을 담당합니다.
- 2,3번째 Dense Block 내의 층들은 일관되게 transition layer의 output에 가장 적은 가중치를 할당합니다(삼각형의 가장 윗 행을 보면 알 수 있습니다.). 이를 통해서 알 수 있는 것은 transition layer가 많은 중복된 특성을 출력하기 때문에 모델 자체적으로 가중치를 높게 부여하지 않는 다는 것을 알 수 있습니다.
- Final classification layer은 전체 Dense Block에 걸쳐 가중치를 사용하지만, 거의 마지막 layer들의 feature-maps에 집중되는 경향이 있는 것을 확인함으로써, 네트워크 후반에는 좀 더 high-level feature들이 생성될 수 있다는 것을 보여줍니다.
6.Conclusion
이번 논문에서는 기존 ResNet과 다르게 바로 앞에 feature map을 skip connection으로 summation해주는 것이 아니라 특정 layer 이전 모든 layer들의 feature-maps을 concatenate 해줌으로써, 모델이 feature들을 재사용할 수 있게 허용하였고, 이를 통해 결과적으로 모델을 더 컴팩트하게 만들어 더 정확하고 효율적인 모델을 학습할 수 있었습니다.